1. Mô hình này thường được sử dụng khi nào?
Mô hình này được sử dụng khi biến phụ thuộc (mình tạm gọi là biến Y nhé) chỉ nhận giá trị 0 và 1. Lưu ý là chỉ có 2 giá trị 0 và 1 thôi, chứ ko phải là nhận giá trị chạy từ 0 đến 1 nha. Ví dụ như chúng ta thực hiện hồi quy để tìm ra các nhân tố ảnh hưởng đến hành vi hút thuốc lá. Nếu Y=1 thì nghĩa là người đó có hút thuốc, và ngược lại là không hút. Biến phụ thuộc này được gọi là biến giả (trong tiếng Anh được gọi là dummy/ binary/ dichotomous variable).
Sau khi hồi quy, giá trị dự báo của Y (predicted Y hoặc là Y^) được giải thích là xác suất xảy ra sự kiện Y = 1 (hay là xác suất hút thuốc lá). Xác suất thì PHẢI nằm trong khoảng (0,1) nghĩa là từ 0% đến 100%.
2. Vì sao không nên dùng OLS?
Giống như mình nói ở trên, giá trị ước lượng của Y phải nằm trong khoảng (0,1). Tuy nhiên, ước lượng OLS không xem xét đến giới hạn này. Vậy nên, xác suất Y =1 theo các hệ số ước lượng OLS hoàn toàn có thể vượt quá giới hạn này, dẫn đến kết quả ước lượng không hợp lý. Đây có lẽ là lý do rõ ràng nhất để giải thích vì sao chúng ta không nên dùng OLS trong trường hợp biến phụ thuộc là biến giả.
Bên cạnh đó là các lý do về mặt kỹ thuật kinh tế lượng. Ví dụ như, ước lượng OLS luôn giả định là xác suất xảy ra Y = 1 luôn luôn tuyến tính với các biến giải thích. Giả định về sai số (error term) tuân theo phân phối chuẩn không thể đạt được khi biến phụ thuộc chỉ nhận giá trị 0 và 1. Và cuối cùng, sai số của mô hình đối với các quan sát là khác nhau nên các kiểm định độ tin cậy sẽ không chính xác.
Tóm lại là, khi biến phụ thuộc chỉ nhận hai giá trị 0 và 1, chúng ta cần phải dùng mô hình logit hoặc probit.
3. Chuyện gì xảy ra ở phía sau các câu lệnh?
Mình sẽ nói về mô hình logit trước nhé. Giả sử mô hình chúng ta cần ước lượng là:
Y = BX + u
Trong đó, biến Y là biến chỉ nhận hai giá trị 0 và 1.
Mô hình logit sẽ dựa trên giả định rằng sai số của mô hình sẽ tuân theo phân phối logistic. Khi đó:
Xác suất để Y = 1 sẽ được tính là:![]()
Hoặc xác suất để Y = 0 sẽ được tính là: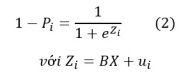
Cả 2 mô hình này đều là mô hình hồi quy phi tuyến tính vì hệ số hồi quy beta nằm trong số mũ.
Vậy nên, một bước biến đổi mô hình nữa sẽ được thực hiện. Chúng ta sẽ lấy xác suất Y = 1 chia cho xác suất Y = 0. Ta sẽ có:
Mô hình vẫn chưa về dạng tuyến tính được, nên chúng ta sẽ tiếp tục thực hiện thêm một bước biến đổi mô hình nữa – đó là lấy log ở cả hai vế của mô hình. Ta sẽ có:
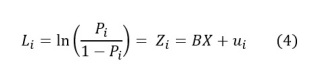
Lúc này, mô hình đã trở về dạng tuyến tính. Hệ số Pi/1-Pi được gọi là Odd ratio. Hệ số này được định nghĩa theo cách mà nó được tính toán luôn đó các bạn.
Tất nhiên là chúng ta sẽ không cần phải thực hiện các bước này. STATA sẽ tự động thực hiện tất cả các bước này. Khi thực hiện hồi quy logit nghĩa là ta đang thực hiện hồi quy tuyến tính giữa log của odd ratio với các biến độc lập X.
4. Giải thích mô hình logit như thế nào?
Ta không thể nào giải thích mô hình logit giống như mô hình tuyến tính khác được bởi vì biến phụ thuộc của chúng ta bây giờ là log của odd ratio.
Nhưng nếu muốn giải thích sát nghĩa nhất thì chúng ta cần phải nói rõ: Khi biến X tăng 1 đơn vị thì log của hệ số odd sẽ thay đổi beta đơn vị.
Cách giải thích này hơi ngộ đúng không. Vậy nên, thông thường chúng ta chỉ giải thích về mối quan hệ giữa biến độc lập và biến phụ thuộc thôi. Khi biến phụ thuộc tăng (nghĩa là hệ số hồi quy dương) với các điều kiện khác không đổi (ceteris paribus) thì hệ số odd cũng tăng theo (nghĩa là xác suất Y = 1 tăng). Trong ví dụ hút thuốc lá ở trên thì chúng ta giải thích là xác suất hút thuốc lá sẽ tăng. Ngược lại, khi hệ số hồi quy là âm thì xác suất của Y = 1 sẽ giảm với các điều kiện khác không đổi.
Khi ước lượng được các hệ số hồi quy rồi, ta có thể dễ dàng tính được xác suất của Y=1 dựa trên công thức (1) ở trên nhé.
5. Mô hình Logit và Probit khác nhau như thế nào?
Mô hình Logit và Probit thường cho các kết quả hồi quy tương tự nhau và cách thức ước lượng của hai mô hình này cũng khá giống nhau. Điểm khác nhau của hai mô hình nằm ở công thức tính xác suất Y = 1 và Y = 0. Mô hình Probit giả định sai số sẽ tuân thủ phân phối chuẩn. Trên cơ sở đó, xác suất Y = 1 sẽ được tính như sau:
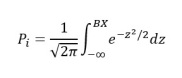
Và xác suất Y = 0 sẽ bằng 1-Pi.
Cách giải thích hệ số hồi quy của hai mô hình này là tương tự nhau. Khi có ước lượng của các hệ số hồi quy rồi thì ta có thể đưa vào công thức trên để tính ra xác suất. Thấy có vẻ phức tạp quá đúng ko? Đừng lo, các phần mềm phân tích dữ liệu như STATA đều giúp chúng ta tính được tất cả các xác suất cho tất cả các quan sát trong nháy mắt thôi.