Vấn đề 1: Trước khi chạy mô hình
Bạn cần phải xem xét dạng dữ liệu và loại dữ liệu mà bạn sử dụng là loại nào: Dữ liệu cắt ngang, dữ liệu chuỗi thời gian hay dữ liệu bảng (như bài viết lần trước ad đã đăng). Chúng ta cũng có thể phân loại nó theo kiểu dữ liệu Likert 5 điểm hoặc 7 điểm (thường dùng trong nghiên cứu marketing về sự hài lòng), dữ liệu nhị thức (0 và 1) hay dữ liệu liên tục (ví dụ dữ liệu về tổng tài sản của công ty qua các năm). VỚI MỖI DẠNG DỮ LIỆU VÀ LOẠI DỮ LIỆU KHÁC NHAU CHÚNG TA SẼ CÓ CÁCH XỬ LÝ DỮ LIỆU VÀ PHƯƠNG PHÁP HỒI QUY KHÁC NHAU VÀ KẾT QUẢ CŨNG SẼ CÓ NHỮNG HÀM Ý KHÁC NHAU. Đây là điều tiên quyết chúng ta cần phải nhớ nhé.
Thông thường, trong quy trình thực hiện một nghiên cứu định lượng, bước đầu tiên mà chúng ta phải thực hiện là thực hiện thống kê mô tả, lập ma trận tương quan, hoặc kiểm tra tính dừng (thường thực hiện đối với dữ liệu theo chuỗi thời gian), v.v…. Đối với mỗi loại dữ liệu khác nhau, chúng ta lại có những cách thực hiện khác nhau [Đọc lại điều tiên quyết]. Ad ví dụ để các bạn dễ hình dung nhé. Trong các nghiên cứu có trình bày về ma trận tương quan thì họ rất hay sử dụng phương pháp Pearson. Tuy nhiên, phương pháp này chỉ phù hợp với loại dữ liệu liên tục thôi nhé. Chính vì thế, khi dùng phương pháp này với dạng dữ liệu likert 5 điểm thì không phù hợp lắm đâu. Dẫu vậy, trong các nghiên cứu trên thế giới người ta vẫn sử dụng và người ta “treated” nghĩa là nhắm mắt cho qua để sử dụng ma trận tương quan này. Thế thì nếu đúng chúng ta nên sử dụng phương pháp nào để tính hệ số tương quan cho cho Likert 5 điểm nhỉ? Về vấn đề này, chúng ta sẽ tìm hiểu sau hơn ở những bài sau nhé.
Nếu các bạn có bất cứ vấn đề nào, có thể nhắn tin cho Ad qua FB nhé. Trong quá trình nghiên cứu, Ad gặp rất nhiều bạn thật sự còn nhầm lẫn các phương pháp với nhau, hoặc sử dụng sai cách, v.v mà không có những hỗ trợ kịp thời.
Vấn đề 2: Khi chạy mô hình hồi quy
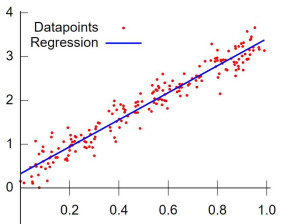
Về cơ bản, các mô hình nghiên cứu được phân thành hai nhóm chính: Mô hình tuyến tính và mô hình phi tuyến tính. Mô hình tuyến tính, có nghĩa là mối quan hệ giữa x – biến độc lập và y – biến phụ thuộc được thể hiện bằng một đường thẳng. Hình vẽ sau là ví dụ về một mối quan hệ tuyến tính này. Các chấm màu đỏ là thể hiện cho các điểm dữ liệu đó. Mô hình được thể hiện bằng đường thẳng màu xanh. Các bạn có thấy các điểm dữ liệu xoay quanh đường màu xanh này không?
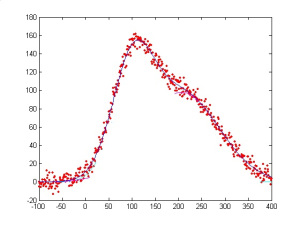
Mô hình phi tuyến tính có nghĩa là mối quan hệ giữa y và x không phải là đường thẳng, vậy thì có thể là hình quả chuông, hoặc đường cong đó các bạn. Các vấn đề nghiên cứu đa dạng nên các mô hình thể hiện cho các mối quan hệ cũng vô cùng nhiều luôn. Các bạn xem hình vẽ dưới để dễ hình dung nhé. Các điểm dữ liệu tạo hình theo kiểu hình chuông, thể hiện cho mối quan hệ phi tuyến tính nè. Vi diệu quá phải ko các bạn.
Nếu như mình thiết kế mô hình sai hoặc là không xử lý dữ liệu kỹ càng thì kết quả hồi quy sẽ rất khó lường.
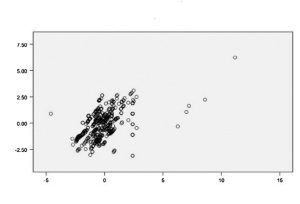
Ví dụ như thế này nè các bạn. Các điểm dữ liệu không tập hợp thành một dạng hình gì cả nên làm sao để mình kết luận được mối quan hệ giữa x và y phải không?
Trong những bài viết cụ thể sau, Ad sẽ giới thiệu với các bạn về các phương pháp hồi quy đối với các mô hình cụ thể và các dạng dữ liệu cụ thể nhé. Đồng thời, Ad cũng sẽ hướng dẫn các bạn cách đọc hiểu các kết quả và ý nghĩa của kết quả luôn nha.
Vấn đề 3: Sau khi chạy hồi quy
Không phải sau khi chúng ta chạy ra mô hình thì chúng ta có thể báo cáo kết quả ngay đâu nhé. Nếu như bạn có tầm 1000 cặp x và y như vậy, liệu chúng ta có đủ tự tin các hệ số chúng ta tìm ra là chuẩn không? Chúng ta cần phải kiểm tra mô hình của chúng ta nhé. Công đoạn này hay được gọi là Post-estimation để phát hiện “bệnh” của mô hình.