1. Chọn mẫu xác suất ngẫu nhiên đơn giản (Simple Random Sampling)
Là một phương pháp chọn mẫu không hạn chế, phương pháp chọn mẫu xác suất ngẫu nhiên đơn giản là hình thức đơn giản nhất, thuần nhất của cách chọn mẫu xác suất. Khi mà tất cả các mẫu xác suất đều phải chọn lựa từng cá thể (đơn vị nghiên cứu) với một xác suất khác không cho trước thì phương pháp chọn mẫu ngẫu nhiên đơn giản được coi là một trường hợp đặc biệt vì mỗi một cá thể đều được lựa chọn với một xác suât biết trước và hoàn toàn ngang bằng nhau.
Xác suất chọn lựa = cỡ mẫu ÷ kích cỡ của dân số (%)
Để thực hiện chọn mẫu ngẫu nhiên đơn giản, việc đầu tiên là chúng ta phải có khung mẫu, hay chính là danh sách tất cả các cá thể (thành viên) của dân số mục tiêu. Dựa trên danh sách này, chúng ta sẽ đánh số và sử dụng bảng ngẫu nhiên để chọn lựa ra các cá thể (rút mẫu) để bảo đảm mọi cá thể đều có xác suất được chọn như nhau.
2. Chọn mẫu xác suất phức tạp (Complex Probability Sampling)
Một mẫu được coi là có hiệu quả hơn về phương diện thống kê là một mẫu mà nó có thể cho kích cỡ mẫu nhỏ hơn với một mức độ chính xác cho trước (sai số chuẩn của trung bình hoặc của tỷ lệ). Một mẫu được coi là có hiệu quả về phương diện kinh tế là một mẫu có thể đạt được một mức độ chính xác cho trước với chi phí thấp.
Ở các phần dưới đây, chúng ta sẽ thảo luận bốn cách thức chọn mẫu xác suất có khả năng thay thế nhau là: (1) chọn mẫu hệ thống (systematic sampling); (2) chọn mẫu phân tầng (stratified sampling); (3) chọn mẫu theo nhóm hoặc phân tổ (cluster
sampling); và (4) chọn mẫu nhiều giai đoạn.
a. Chọn mẫu hệ thống (Systematic sampling)
Theo cách tiếp cận này, ta chọn lấy các thành phần thứ kth trong dân số, bắt đầu với một con số khởi điểm ngẫu nhiên trong phạm vi từ 1 đến k. Thành phần thứ kth , còn gọi là bước nhảy (skip interval), được tính bằng cách chia cỡ mẫu cho kích cỡ của dân số.
K = bước nhảy = dân số ÷ cỡ mẫu
Chúng ta cũng phải có khung mẫu chính xác và hoàn thiện.
Thủ tục để tiến hành chọn mẫu hệ thống theo các bước sau:
- Xác định, lập danh sách và đánh số các cá thể của dân số
- Xác định bước nhảy (k)
- Xác định con số khởi đầu một cách ngẫu nhiên
- Rút mẫu bằng cách chọn tất cả các cá thể theo các bước nhảy kth.
Phương pháp chọn mẫu hệ thống có ưu điểm là đơn giản và mềm dẻo. Tuy vậy, phương pháp này cũng có thể sinh ra các thiên lệch khó thấy. Đầu tiên là tính chất chu kỳ của dân số có thể xảy ra song song với tỷ lệ mẫu (bước nhảy). Ngoài ra, các cá thể của dân số có thể đã được sắp xếp theo một trật tự đơn chiều nào đó. Trong nghiên cứu kinh tế, các dân số thường được sắp xếp theo trật tự sẵn có. Ví dụ, chúng ta có danh sách các cá nhân, hoặc hộ giađình sắp xếp từ nghèo đến giàu, hoặc ngược lại; hoặc danh sách các hộ nông nghiệp sắp xếp theo quy mô tăng dần về diện tích đất canh tác, v.v. Chính vì vậy, khi chọn cá thể, chúng ta có thể bị thiên lệch về một phía nào đó của dãy số liệu.
Để tránh tình trạng thiên lệch như vậy, chúng ta nên:
- Sắp xếp ngẫu nhiên dân số trước khi chọn mẫu
- Chọn con số khởi điểm một cách ngẫu nhiên vài lần khi bắt đầu chọn mẫu
- Lặp lại cách chọn mẫu như vậy cho các mẫu khác.
Nếu thực hiện tốt, phương pháp này cho hiệu quả thống kê cao hơn phương pháp ngẫu nhiên đơn giản.
b. Chọn mẫu phân tầng (Stratified Sampling)
Hầu hết các dân số đều bao gồm các nhóm cá thể khác nhau. Các nhóm như vậy chính là các nhóm dân số phụ (subpopulation), hay là các tầng (strata). Quá trình chọn mẫu mà các cá thể được chọn lựa theo từng nhóm như vậy được gọi là chọn mẫu ngẫu nhiên phân tầng (stratified random sampling). Phương pháp chọn mẫu phân tầng có hiệu quả thống kê cao hơn phương pháp chọn mẫu ngẫu nhiên đơn giản.
Tại sao chúng ta chọn phương pháp chọn mẫu phân tầng này? Phương pháp này cho chúng ta nhiều lợi ích như:
- Tăng hiệu quả thống kê của mẫu;
- Cung cấp dữ liệu phù hợp để phân tích từng nhóm dân số phụ hay từng tầng, và
- Cho phép sử dụng các phương pháp nghiên cứu và phân tích khác nhau cho cá nhóm dân số phụ khác nhau.
Nếu phân tầng một cách lý tưởng, ta sẽ có sự đồng nhất trong nội bộ từng nhóm và có sự dị biệt giữa các nhóm. Nếu phân tầng càng nhiều thì ta càng có thể tối đa hóa sự khác biệt giữa các nhóm và tối thiểu hóa sự biến thiên trong nội bộ từng nhóm.
Tuy nhiên, chi phí cũng là một yếu tố đáng quan tâm. Nếu tăng số nhóm nghiên cứu lên (số tầng) thì chi phí cũng tăng theo vì chi phí đi đôi với mức độ chọn mẫu chi tiết.
Ngoài ra, cũng phải chú ý đến các yếu tố sau: (1) kích cỡ tổng mẫu cần có và (2) tổng mẫu được phân bổ như thế nào giữa các tầng. Hai vấn đề này quan trọng vì chúng quyết định số cá thể cần có ở từng tầng.
Ví dụ, ta có hạn chế ngân sách nên chỉ có thể chọn cỡ mẫu tối đa là 250. Nếu ta chọn cách chia dân số làm 5 nhóm dân số phụ khác nhau, với tỷ lệ tương đương nhau, thì số lượng cá thể cần quan sát của mỗi mẫu phụ (tương ứng với mỗi nhóm dân số phụ, hay là từng tầng) là 50, tương đương với tỷ lệ 20% tổng mẫu. Số lượng 50 cá thể này có thể bảo đảm mức độ tin cậy về phân tích thống kê. Nhưng nếu chúng ta muốn chia dân số làm 10 nhóm dân số phụ, thì kích cỡ của mẫu phụ chỉ là 25. Số lượng đơn vị nghiên cứu có trong 1 mẫu phụ này có thể không bảo đảm tin cậy về phân tích thống kê.
Đối với cách phân bố mẫu cho các nhóm phụ (tầng) khác nhau, có hai cách là theo tỷ lệ (proportionate) và không theo tỷ lệ (disproportionate).
Đối với cách chọn mẫu phân tầng theo tỷ lệ (proportionate stratified sampling), cỡ mẫu của mỗi mẫu phụ (tầng) theo đúng tỷ lệ của các thành phần có trong từng dân số phụ so với tổng dân số. Cách chọn mẫu phân tầng theo tỷ lệ phổ biến nhiều hơn bất kỳ cách chọn mẫu phân tầng nào khác, bởi vì:
- có hiệu quả thống kê cao hơn phương pháp ngẫu nhiên đơn giản
- dễ thực hiện hơn các phương pháp phân tầng khác
- cung cấp một mẫu tự định trọng số (self-weighting sample); giá trị trung bình tổng thể hoặc tỷ lệ tổng thể có thể được ước lượng một cách dễ dàng.
Quy trình chọn mẫu phân tầng bao gồm các bước sau đây:
- Quyết định các biến số dùng để phân tầng. Trong nghiên cứu kinh tế – xã hội, các biến danh nghĩa thường được dùng để phân chia dân số thành các dân số phụ. Thông thường là các biến nhân khẩu học (ví dụ độ tuổi, giới tính, nghề nghiệp, học vấn, v.v) hoặc các biến thể hiện sự khác biệt về vị thế kinh tế (ví dụ nghèo, cận nghèo, trung bình, khá, giàu).
- Xác định tỷ lệ của từng nhóm dân số phụ so với dân số chung. Để làm được việc này, rõ ràng là chúng ta phải có được khung mẫu của dân số tổng thể, và các khung mẫu của các dân số phụ dựa trên các biến danh nghĩa mà chúng ta dùng để phân chia.
- Chọn lựa cách phân tầng theo tỷ lệ hoặc không theo tỷ lệ tùy theo nhu cầu thông tin nghiên cứu và các rủi ro có thể xảy ra.
- Thiết lập các khung mẫu của các dân số phụ. Mỗi khung mẫu (phụ) thể hiện một tầng (nhóm dân số phụ).
- Trộn ngẫu nhiên các thành phần (cá thể, đơn vị nghiên cứu) trong từng khung mẫu của từng tầng.
- Rút mẫu cho các tầng bằng cách rút mẫu ngẫu nhiên hoặc hệ thống.
c. Chọn mẫu theo nhóm (Cluster Sampling)
Trong một mẫu ngẫu nhiên, mỗi thành phần của dân số được chọn lựa theo từng cá thể. Dân số cũng có thể được chia thành nhiều nhóm chứa đựng các thành phần cá thể mà có thể, một số nhóm như vậy được chọn ngẫu nhiên cho nghiên cứu. Đó chính là nguyên tắc của phương pháp chọn mẫu theo nhóm.
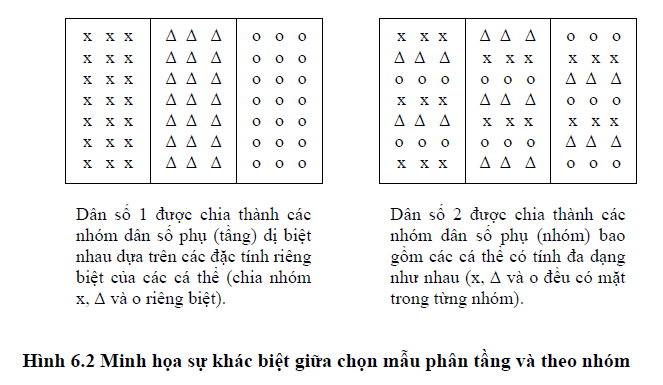
Ta có thể hình dung sự khác biệt giữa chọn mẫu phân tầng và chọn mẫu theo nhóm như sau. Giả sử hai dân số 1 và 2 đều chứa đựng các cá thể khác biệt, nhưng có thể chia làm ba nhóm chính, thể hiện bằng các ký tự x, A và o (Hình 6.3).
Dựa trên tính chất khác biệt này, chúng ta có thể chọn mẫu theo hai cách khác biệt nhau. Cách thứ nhất là chúng ta chia dân số thành 3 nhóm dân số phụ theo các đặc tính x, A và o. Điều này cho phép chúng ta có 3 nhóm dân số phụ (tầng – stratum) bảo đảm sự đồng nhất trong nội bộ từng nhóm và có sự dị biệt giữa các nhóm. Ngược lại, chúng ta cũng có thể chia dân số thành 3 nhóm dân số phụ mà mỗi nhóm đều có các thành phần cá thể đa dạng với các đặc tính x, A và o. Kết quả là, ta có 3 nhóm dân số phụ (clusters) và có thể bảo đảm sự đa dạng hay dị biệt trong nội bộ từng nhóm và có sự đồng nhất giữa các nhóm.
Cách thứ nhất chính là chọn mẫu phân tầng. Cách thứ hai là chọn mẫu theo nhóm.
Hiệu quả thống kê của chọn mẫu theo nhóm thường thấp hơn chọn mẫu ngẫu nhiên đơn giản vì thông thường, các nhóm lại không có sự khác biệt cần thiết, mà lại có sự đồng nhất.

Chọn mẫu theo vùng (Area Sampling)
Hầu hết các nghiên cứu kinh tế đều liên quan đến các dân số mà chúng có thể chia theo các vùng địa lý. Ví dụ khi nghiên cứu tình trạng nghèo đói, ta có thể thấy ở bất kỳ quốc gia nào (trên thế giới) hoặc ở bất kỳ vùng, miền, tỉnh nào (trong phạm vi một quốc gia) đều có người nghèo, giàu khác nhau. Như vậy, khi nghiên cứu, ta có thể chọn lựa một vài vùng miền nào đó thuận tiện cho nghiên cứu, và khi nghiên cứu ở các vùng như trên, ta vẫn bảo đảm có được các cá thể giàu, nghèo khác biệt nhau.
Khi ta có thể chia dân số theo vùng địa lý như vậy thì rõ ràng ta có thể sử dụng phương pháp chọn mẫu theo nhóm. Cách thức chọn mẫu như vậy còn được gọi là chọn mẫu theo vùng, và có thể áp dụng ở mức độ quốc gia, vùng miền, thậm chí các đơn vị theo địa giới hành chính ở quy mô nhỏ hơn.
Thiết kế chọn mẫu theo nhóm
Khi chọn mẫu theo nhóm, kể cả chọn mẫu theo vùng, chúng ta cần trả lời các câu hỏi sau đây:
- Các nhóm đồng nhất với nhau như thế nào?
- Chúng ta tìm các nhóm có kích cỡ bằng nhau hay khác nhau?
- Chúng ta sẽ chọn nhóm có kích cỡ bao nhiêu?
- Chúng ta sẽ áp dụng phân nhóm một giai đoạn (single-stage cluster) hay nhiều giai đoạn (multistage cluster)?
- Kích cỡ của mẫu bao nhiêu là vừa?
d. Chọn mẫu nhiều giai đoạn (Double Sampling – sequential sampling – multiphase sampling)
Trong nghiên cứu thực tế, người ta thường áp dụng phương chọn mẫu nhiều giai đoạn. Phương pháp này cho phép chúng ta sử dụng các thông tin có được từ các cuộc nghiên cứu ban đầu để làm cơ sở cho việc chọn mẫu ở các bước tiếp theo.
Trong nghiên cứu kinh tế, đôi khi chúng ta tiến hành nghiên cứu theo nhiều giai đoạn. Giai đoạn đầu tiên là nghiên cứu khám phá, là giai đoạn mà ta cần tìm hiểu các thông tin cơ bản của dân số mục tiêu thông qua mẫu. Dựa trên các thông tin cơ bản này, ta có thể hiểu về cấu trúc của dân số, và có thể phát hiện sự dị biệt cũng như tương đồng trong nội bộ dân số thông qua các chỉ tiêu thống kê ghi nhận được. Từ đó, chúng ta có thể tiếp tục rút ra các mẫu phụ từ mẫu mà chúng ta đã có để tiếp tục nghiên cứu ở các giai đoạn sau (nghiên cứu sâu).
Loại hình chọn mẫu nhiều giai đoạn thường được áp dụng trong nghiên cứu kinh tế – xã hội. Ở giai đoạn đầu, người ta thường chọn mẫu có cỡ mẫu lớn, thiết kế nội dung nghiên cứu đơn giản nhằm tìm hiểu các thông tin cơ bản của dân số mục tiêu. Sau đó, tùy theo mục tiêu nghiên cứu, người ta thiết kế các nghiên cứu sâu với các nội dung rất chi tiết, nhưng cần số đơn vị nghiên cứu ít hơn. Kết quả nghiên cứu trước cho phép rút ra các tiêu chí phân nhóm phù hợp cũng như bảo đảm khả năng rút các mẫu phụ chứa đựng các đơn vị nghiên cứu phù hợp từ mẫu đã nghiên cứu.
Thông thường, phương pháp chọn mẫu nhiều giai đoạn kết hợp nhiều phương pháp chọn mẫu khác nhau, ví dụ như chọn mẫu phân tầng, chọn mẫu theo nhóm, chọn mẫu hệ thống. Ví dụ sau đây sẽ minh họa rõ hơn.
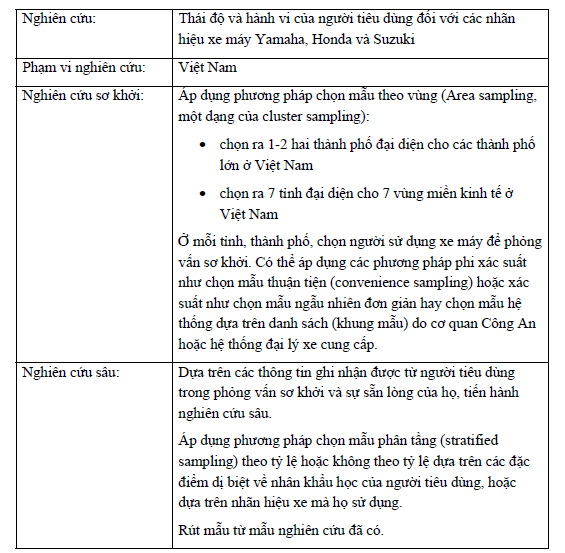
Với ví dụ trên, ta thấy nhà nghiên cứu có thể lựa chọn và áp dụng nhiều phương pháp chọn mẫu khác nhau cho các giai đoạn nghiên cứu khác nhau. Tất nhiên là các phương án chọn lựa còn tùy thuộc rất nhiều vào mục tiêu nghiên cứu, dân số mục tiêu, các chỉ tiêu cần thu thập, khả năng có được khung mẫu, sự dễ dàng, thuận tiện trong nghiên cứu, và khả năng tài chính đáp ứng cho nghiên cứu.
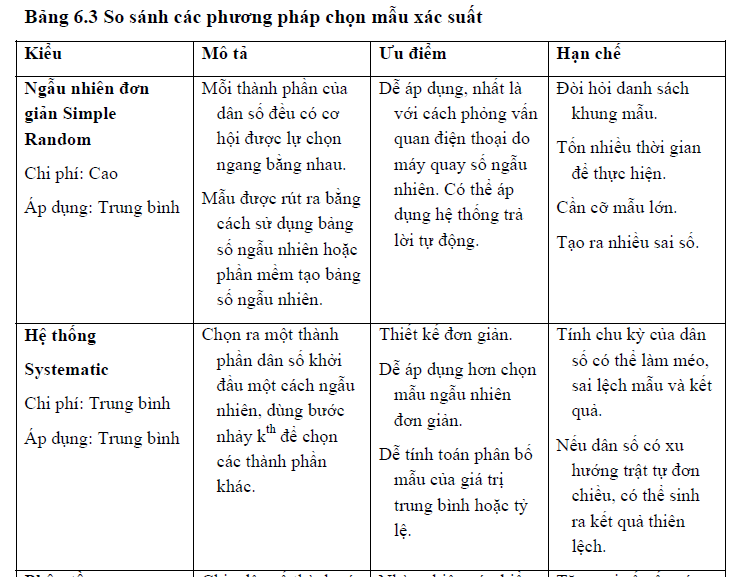
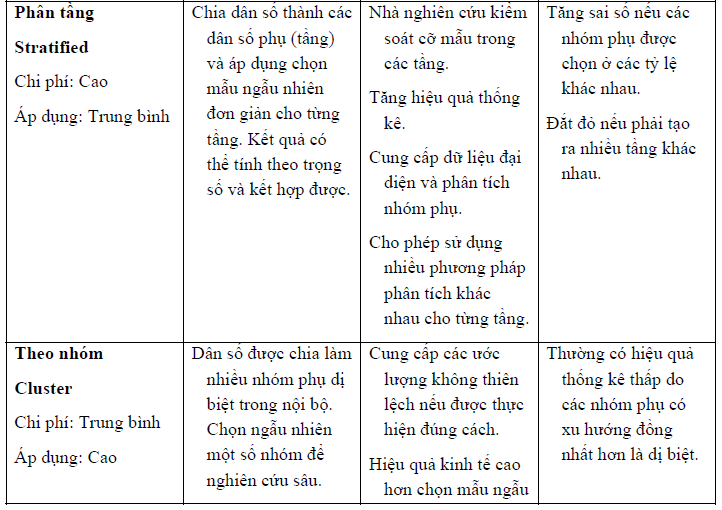
Như vậy, có nhiều phương pháp chọn mẫu xác suất khác nhau, với các ưu điểm và hạn chế của chúng. Bảng 6.3 giúp tóm tắt đặc điểm chính, ưu điểm và hạn chế của từng phương pháp.