1. GIỚI THIỆU
Mục đích của đa số các nghiên cứu thực nghiệm trong kinh tế là giải thích mối quan hệ giữa một biến phụ thuộc Y, theo một hay nhiều biến giải thích (X11, X22, …, Xkk). Để làm điều này, chúng ta muốn biết sự tác động của Xi lên Y như thế nào, cả chiều hướng lẫn độ lớn của tác động. Trả lời câu hỏi này, chúng ta phải thu thập mẫu để có được kết quả ước lượng không chệch tác động của X lên Y. Để kết quả ước lượng là không thiên chệch đòi hỏi chúng ta phải kiểm soát các biến nhiễu, cả các biến quan sát được lẫn các biến không quan sát được. Đối với các biến nhiễu quan sát được, chúng ta có thể sử dụng mô hình hồi quy tuyến tính đa biến cổ điển (MCLR). Đối với các biến nhiễu không quan sát được, tuỳ vào đặc điểm khác nhau giữa các đối tượng và thời gian mà chúng ta lựa chọn mô hình hồi quy tác động cố định hay tác động ngẫu nhiên. Cả hai mô hình hồi quy này đòi hỏi chúng ta phải sử dụng dữ liệu bảng.

Bài viết này tập trung trình bày nguyên tắc của các phương pháp ước lượng dữ liệu bảng chứ không đi sâu vào các vấn đề về thủ tục kiểm định liên quan.
2. DỮ LIỆU BẢNG
- Mô hình hồi tác động cố định (Fixed-effects) và tác động ngẫu nhiên (random-effects) được sử dụng trong phân tích dữ liệu bảng (đôi khi còn được gọi là dữ liệu dài: longitudinal data). Dữ liệu bảng là sự kết hợp của dữ liệu chéo (cross-section) và dữ liệu thời gian (time series). Để thu thập dữ liệu bảng, chúng ta phải thu thập nhiều đối tượng (units) giống nhau trong cùng một hoặc nhiều thời điểm. Chẳng hạn, chúng ta có thể thu thập các dữ liệu của cùng các cá nhân, công ty, trường học, thành phố, quốc gia… trong giai đoạn từ năm 2000 đến 2014.
- Sử dụng dữ liệu bảng có hai ưu điểm lớn như: i) Dữ liệu bảng cho các kết quả ước lượng các của tham số trong mô hình tin cậy hơn; ii) Dữ liệu bảng cho phép chúng ta xác định và đo lường tác động mà những tác động này không thể được xác định và đo lường khi sử dụng sử dụng chéo hoặc dữ liệu thời gian.
3. MÔ HÌNH TÁC ĐỘNG CỐ ĐỊNH (FIXED EFFECTS MODEL)

Phương pháp ước lượng

4. MÔ HÌNH TÁC ĐỘNG NGẪU NHIÊN (RANDOM EFFECTS MODEL)

Phương pháp ước lượng
Ước lượng OLS cho mô hình tác động ngẫu nhiên sẽ cho các tham số ước lượng không chệch nhưng lại không hiệu quả. Hơn nữa, các ước lượng của sai số chuẩn và do đó thống kê t sẽ không còn chính xác. Sở dĩ như vậy là vì ước lượng OLS bỏ qua sự tự tương quan trong thành phần sai số μit. Để kết quả ước lượng không chệch và hiệu quả, chúng ta có thể sử dụng ước lượng GLS khả thi (FGLS) để khắc phục hiện tượng sai số nhiễu tự tương quan. Ước lượng FGLS còn được gọi là ước lượng tác động ngẫu nhiên (Random effects estimator).
Ngoài hai phương pháp tác động cố định và tác động ngẫu nhiên, trong một số trường hợp nhà nghiên cứu vẫn sử dụng ước lượng OLS thô (Pooled OLS) cho dạng dữ liệu thu thập này. Ước lượng thô là ước lượng OLS trên tập dữ liệu thu được của các đối tượng theo thời gian, do vậy nó xem tất cả các hệ số đều không thay đổi giữa các đối tượng khác nhau và không thay đổi theo thời gian (Gujarati, 2004 trang 641).
5. LỰA CHỌN MÔ HÌNH
Câu hỏi đặt ra là mô hình nào sẽ là mô hình phù hợp: Pooled OLS, FE hay RE. Sự phù hợp của ước lượng tác động ngẫu nhiên và tác động cố định được kiểm chứng trên cơ sở so sánh với ước lượng thô.
- Cụ thể, ước lượng tác động cố định được kiểm chứng bằng kiểm định F với giả thuyết H0 cho rằng tất cả các hệ số vi đều bằng 0 (nghĩa là không có sự khác biệt giữa các đối tượng hoặc các thời điểm khác nhau). Bác bỏ giả thuyết H0 với mức ý nghĩa cho trước (mức ý nghĩa 5% chẳng hạn) sẽ cho thấy ước lượng tác động cố định là phù hợp. Đối với ước lượng tác động ngẫu nhiên, phương pháp nhân tử Lagrange (LM) với kiểm định Breusch-Pagan được sử dụng để kiểm chứng tính phù hợp của ước lượng (Baltagi, 2008 trang 319). Theo đó, giả thuyết H0 cho rằng sai số của ước lượng thô không bao gồm các sai lệch giữa các đối tượng var(vi) = 0 (hay phương sai giữa các đối tượng hoặc các thời điểm là không đổi). Bác bỏ giả thuyết H0, cho thấy sai số trong ước lượng có bao gồm cả sự sai lệch giữa các nhóm, và phù hợp với ước lượng tác động ngẫu nhiên.
- Kiểm định Hausman sẽ được sử dụng để lựa chọn phương pháp ước lượng phù hợp giữa hai phương pháp ước lượng tác động cố định và tác động ngẫu nhiên (Baltagi, 2008 trang 320; Gujarati, 2004 trang 652). Giả thuyết H0 cho rằng không có sự tương quan giữa sai số đặc trưng giữa các đối tượng (vi) với các biến giải thích Xit trong mô hình. Ước lượng RE là hợp lý theo giả thuyết H0 nhưng lại không phù hợp ở giả thuyết thay thế. Ước lượng FE là hợp lý cho cả giả thuyết H0 và giả thuyết thay thế. Tuy nhiên, trong trường hợp giả thuyết H0 bị bác bỏ thì ước lượng tác động cố định là phù hợp hơn so với ước lượng tác động ngẫu nhiên. Ngược lại, chưa có đủ bằng chứng để bác bỏ H0 nghĩa là không bác bỏ được sự tương quan giữa sai số và các biến giải thích thì ước lượng tác động cố định không còn phù hợp và ước lượng ngẫu nhiên sẽ ưu tiên được sử dụng.
6. KẾT QUẢ
Sử dụng phần mềm STATA cho tập dữ liệu mus08psidextract.dta với dữ liệu bảng cân bằng 4165 quan sát gồm 7 giai đoạn thời gian (T=7) và 595 đối tượng người lao động (n=595). Kết quả ước lượng mức lương của người lao động (lwage) theo số năm kinh nghiệm (exp), số năm kinh nghiệm bình phương (exp2), số giờ làm việc trong tuần (wks) và số năm đi học của người lao động (ed) theo 3 mô hình Pooled OLS, Fixed effect (FE) và Random effect (RE) được thể hiện như sau:

Kết quả ước lượng mô hình mức lương của người lao động theo: Pooled OLS, Fixed effect và Random effect
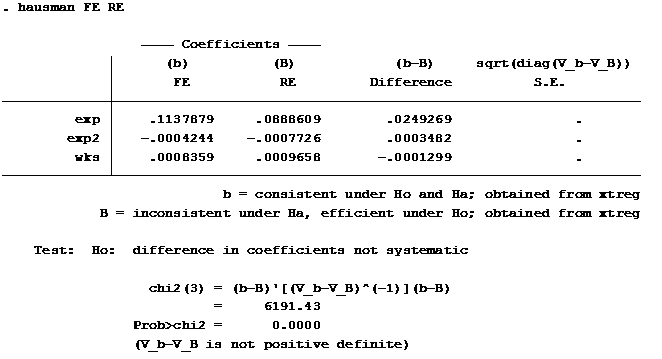
Kết quả kiểm định Hausman về sự lựa chọn mô hình Fixed effect và Random effect