Thống kê mô tả (tiếng Anh: Descriptive Statistics) là các hệ số mô tả ngắn gọn hay tóm tắt một tập dữ liệu nhất định, có thể là đại diện cho toàn bộ hoặc một mẫu của một tổng thể.
Các câu hỏi định lượng Likert với 5, 7, 9 mức độ. Chúng ta sẽ sử dụng kỹ thuật thống kê trung bình trên SPSS để đánh giá khái quát về nhận định của đối tượng khảo sát với các câu Likert này.
Gọi tóm gọn là thống kê trung bình, tuy nhiên, thống kê này sẽ hiển thị đầy đủ các chỉ số trung bình (mean), giá trị nhỏ nhất (min), giá trị lớn nhất (max), độ lệch chuẩn (standard deviation),…
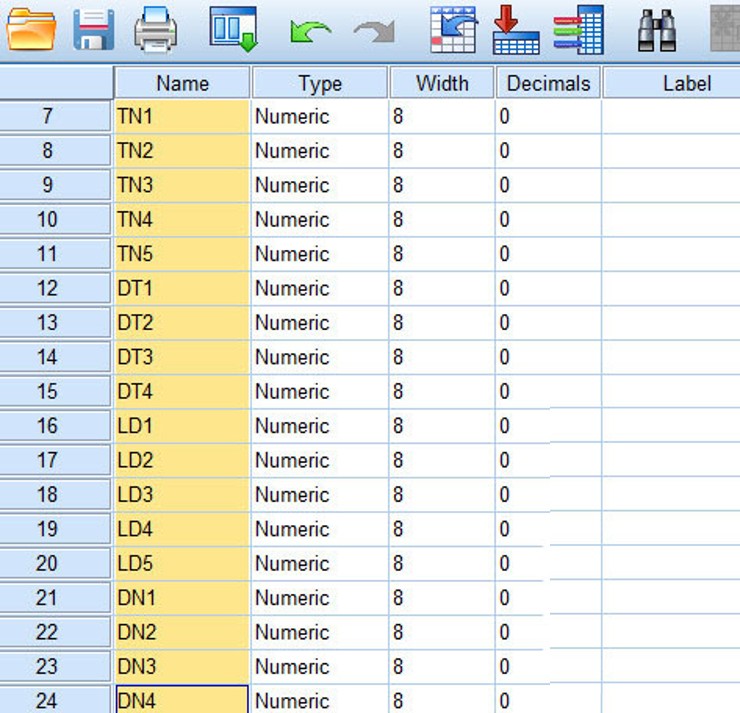
Ở đây, mình có một file dữ liệu SPSS gồm các câu Likert 5 mức độ. Mỗi nhóm nhân tố gồm các biến quan sát nhỏ bên trong: nhóm TN, nhóm DT, nhóm DN. Mình sẽ thực hiện phân tích thống kê trung bình trên SPSS với các biến này.
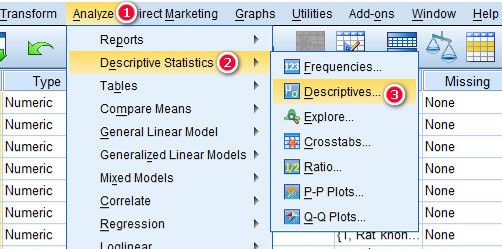
Để phân tích thống kê mô tả trung bình trên SPSS, các bạn truy cập vào Analyze > Descriptive Statistics > Descriptives.
Giao diện cửa sổ sẽ hiện như bên dưới. Đưa hết tất cả các biến cần chạy thống kê mô tả trung bình từ mục bên trái sang mục bên phải Variable, sau đó nhấp vào OK.

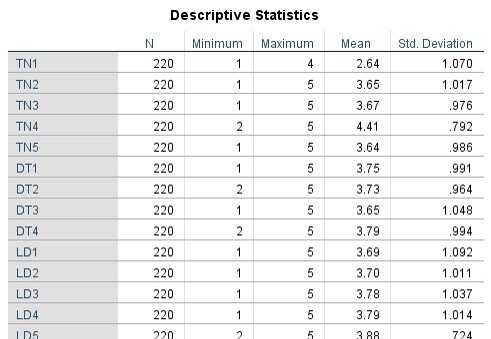
Kết quả output sẽ xuất ra bảng thống kê mô tả như bên dưới. Các bạn có thể tách bảng chính này thành bảng con từng nhóm TN, DT, LD, DN,… hoặc khi chạy thống kê trung bình, thay vì đưa tất cả các biến ở nhiều nhóm vào, bạn sẽ đưa lần lượt từng nhóm.
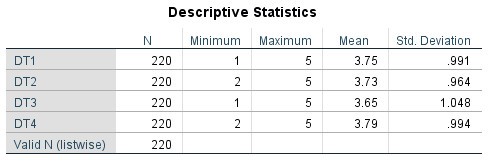
(Bảng kết quả khi đưa nhiều nhóm vào cùng nhau)
Chúng ta sẽ xem ý nghĩa của từng cột trong bảng thống kê trung bình:
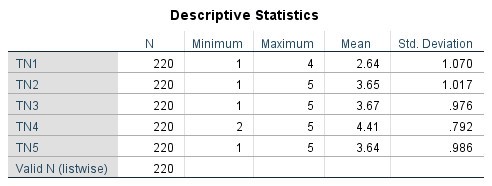
– Cột N: cỡ mẫu nghiên cứu
– Cột Minimum: giá trị nhỏ nhất của biến. Như bên dưới là biến TN, giá trị nhỏ nhất của TN1, TN2, TN3, TN5 đều là 1, trong khi giá trị nhỏ nhất của biến TN4 là 2.
– Cột Maximum: giá trị lớn nhất của biến. Ví dụ bên dưới từ biến TN2 đến TN5 giá trị lớn nhất đều là 5 trong khi biến TN1 giá trị lớn nhất là 4.
– Cột Mean: giá trị trung bình của biến. Đây là cột mang nhiều ý nghĩa giải thích nhất trong bảng. Thang đo Likert 5 mức độ, chúng ta có mức điểm 3 là trung gian, nếu thiên về 3-5 nghĩa là đáp viên đồng ý với quan điểm của biến đưa ra. Ngược lại, nếu thiên về 1-3, đáp viên không đồng ý với quan điểm của biến. Biến TN1 có Mean = 2.64 < 3, như vậy dữ liệu cho thấy rằng, mức độ đồng ý của đối tượng khảo sát là dưới mức trung gian 3. Trong khi đó, biến TN2, TN3, TN5 có mức Mean nằm giữa khoảng 3-4. Riêng biến TN4, mức Mean = 4.41 > 4 cho thấy rằng đáp viên đang rất đồng ý với quan điểm của TN4.
– Cột Std. Deviation: độ lệch chuẩn của biến. Giá trị này càng nhỏ cho thấy, đáp viên trả lời các con số đáp án không chênh lệch nhau nhiều. Ngược lại nếu giá trị này cao, thể hiển rằng đối tượng khảo sát có nhận định rất khác biệt nhau đối với biến đó, nên mức điểm cho chênh lệch nhau khá nhiều.
(Bảng kết quả khi đưa vào từng nhóm)
Bên cạnh việc một số nhà nghiên cứu đánh giá Mean qua mức trung lập (trong trường hợp này là 3), một số nhà nghiên cứu khác thực hiện chia khoảng giá trị để phân đoạn mức độ. Ví dụ, với thang đo Likert 5 mức, có thể chia đoạn theo công thức sau:
Giá trị khoảng cách = (Maximum – Minimum) / n = (5-1)/5 = 0.8
Ý nghĩa các mức như sau:
1.00 – 1.80: Rất không đồng ý
1.81 – 2.60: Không đồng ý
2.61 – 3.40: Không ý kiến
3.41 – 4.20: Đồng ý
4.21 – 5.00: Rất đồng ý
Thông thường, với bảng thống kê trung bình sau khi đã được xuất ra output SPSS. Các bạn nên copy vào Excel hoặc Word, sau đó chèn thêm cột mô tả ý nghĩa tên biến để trình bày vào bài sẽ chuyên nghiệp hơn.
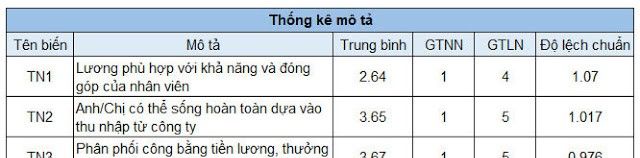
Cũng như lưu ý ở phần thống kê tần số, các bạn cần nhớ rằng, ở thống kê mô tả, việc đọc bảng kết quả chỉ dừng lại ở mức độ “đọc” các chỉ số hiển thị mean, min, max, S.D. Các bạn không nên vội diễn giải sâu ý nghĩa, giá trị mean thấp như vậy thì mang hàm ý giải pháp, kiến nghị gì. Thống kê trung bình chỉ dừng lại là mô tả khái quát mức đánh giá của đối tượng khảo sát ở mức điểm bao nhiêu trên thang đo được sử dụng, mức điểm nhỏ nhất, lớn nhất và độ lệch chuẩn của mỗi biến quan sát là bao nhiêu. Chúng ta sẽ đi sâu phần diễn giải sau khi đã hoàn thành tất cả các kiểm định định lượng, từ kết quả định lượng đó, chúng ta mới đi ngược lại phần phân tích chi tiết hơn thống kê mô tả.