1. Định nghĩa:
Phương sai sai số thay đổi là hiện tượng mà phương sai của các sai số ước lượng không bằng nhau. Từ heteroscedasticity nghĩa là unequal variance. Hiện tượng này thường hay xảy ra đối với dữ liệu cắt ngang (cross-sectional data).
2. Nguyên nhân xuất hiện:
Nguyên nhân chính dẫn đến sự xuất hiện của hiện tượng này có lẽ là do sự tồn tại của các outliers trong biến. Outliers là các quan sát của biến mà có giá trị quá khác biệt so với các quan sát còn lại. Hoặc là các quan sát của cùng một biến nhưng lại được đo lường với những thang đo khác nhau. Ví dụ khi đo lường thu nhập, bạn dùng đơn vị tỷ đồng cho những người có thu nhập cao, nhưng lại vô tình dùng đơn vị triệu đồng cho những người có thu nhập thấp hơn. Ngoài ra, hiện tượng này cũng có thể xảy ra trong trường hợp sai dạng hàm hoặc sai sót trong quá trình biến đổi dữ liệu.
3. Hậu quả:
Nếu như mô hình chỉ xảy ra lỗi phương sai sai số thay đổi thôi thì ước lượng OLS vẫn là ước lượng ko bị thiên lệch và nhất quán (unbiased and consistent), tuy nhiên nó không phải là ước lượng tốt nhất (hiệu quả nhất) nữa. Bởi vì, phương sai của sai số trong trường hợp này không thể đạt được giá trị nhỏ nhất nữa. Khi đó, các kiểm định hệ số hồi quy và kiểm định F của mô hình trở nên không đáng tin cậy. Vì vậy, việc đưa ra các kết luận dựa trên các kiểm định này sẽ không chính xác.
4. Cách phát hiện:
Mình sẽ sử dụng bộ dữ liệu auto có sẵn của STATA để minh hoạ nhé. Để sử dụng bộ dữ liệu này thì các bạn chỉ cần gõ lệnh sysuse auto.dta là được.
Có hai cách phát hiện hiện tượng này: đó là dùng hình vẽ hoặc dùng các kiểm định.
Cách 1: Vẽ đồ thị giữa sai số và giá trị ước lượng của biến Y và quan sát
Đầu tiên mình sẽ chạy hồi quy mô hình PRICE = alpha + beta1*MPG + beta2*WEIGHT
Mình đang kiểm tra xem mức độ hao xăng và trọng lượng của xe thì có ảnh hưởng ntn đến giá thành của một chiếc xe.

Sau đó, mình sẽ dùng lệnh rvfplot để có thể vẽ được đồ thị giữa sai số và giá trị ước lượng của biến phụ thuộc trong mô hình. Mình thêm một cái option trong câu lệnh là yline(0) để đồ thị hiện ra đường thẳng tại mức sai số = 0. Giá trị 0 là giá trị trung bình của sai số.
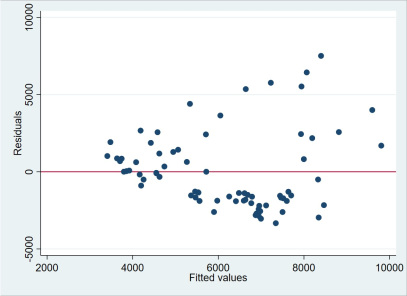
Các chấm xanh trong hình vẽ thể hiện cho vị trí của các sai số đối với từng giá trị ước lượng của biến Y (fitted values). Nếu khoảng cách của các chấm xanh này đến đường giá trị trung bình tương tự nhau thì chúng ta có thể ngầm hiểu là không có hiện tượng phương sai sai số thay đổi xảy ra. Tuy nhiên, trong hình vẽ trên, ta thấy càng về phía bên phải thì các chấm xanh càng cách xa đường giá trị trung bình hơn. Điều này ngầm báo hiệu cho chúng ta rằng có hiện tượng phương sai sai số thay đổi xảy ra. Ta có thể dùng các kiểm định chuyên dụng để kiểm tra lại lần nữa cho chắc.
Cách 2: Dùng các kiểm định chuyên dụng
Có 2 kiểm định mà chúng ta có thể sử dụng đó là kiểm định Breusch-Pagan và kiểm định White. Cả hai kiểm định này đều có cùng một giả thuyết, đó là:
Ho: Phương sai sai số là bằng nhau/không đổi (Constant variance/Homoskedasticity)
H1: Phương sai sai số không bằng nhau/thay đổi (Unequal variance/Heteroskedasticity)
Nếu như chúng ta bác bỏ giả thuyết Ho thì nghĩa là mô hình hồi quy có hiện tượng phương sai sai số thay đổi. Ngược lại nếu chúng ta chấp nhận giả thuyết H0 thì nghĩa là không có hiện tượng PSSS thay đổi xảy ra.
Cả hai kiểm định này đều sẽ cung cấp cho chúng ta một hệ số thống kê đi cùng với giá trị P-value tương ứng. Như vậy, nếu P-value>=0.1 thì chúng ta có thể an tâm không thể bác bỏ giả thuyết H0 và vì vậy mô hình của chúng ta okay. Ngược lại, nếu P-value <0.1 thì điều đó có nghĩa là mô hình gặp phải hiện tượng PSSS thay đổi.
Mình xin phép bỏ qua phần giới thiệu về quá trình xây dựng nên hai kiểm định này nhé. Nếu bạn nào quan tâm, mình có thể gửi tài liệu về vấn đề này cho các bạn qua email.
Trong bài viết này mình chỉ hướng dẫn cách thức thực hiện hai kiểm định này trong STATA thôi.
- Đối với kiểm định Breusch-Pagan
Sau khi thực hiện lệnh hồi quy, bạn dùng câu lệnh estat hettest ngay sau đó thì STATA sẽ báo kết quả của kiểm định này cho bạn.

Ví dụ trong trường hợp này, P-value là 0.0001. Điều này có nghĩa là mô hình có hiện tượng PSSS thay đổi. Kết quả này phù hợp với cách kiểm tra bằng hình vẽ mà mình nói ở trên.
- Đối với kiểm định White
Sau khi thực hiện lệnh hồi quy, chúng ta dùng câu lệnh estat imtest, white nhé. Kết quả của kiểm định White như sau:

Chúng ta có thể thấy giá trị P-value = 0.0066, vẫn quá nhỏ so với 0.1. Vậy nên chúng ta phải bác bỏ giả thuyết H0 và kết luận rằng mô hình có hiện tượng PSSS thay đổi.
4*. Làm thế nào phát hiện hiện tượng PSSS thay đổi trong dữ liệu bảng?
Dữ liệu bảng là sự kết hợp giữa dữ liệu thời gian (time-series) và dữ liệu cắt ngang (cross-sectional) nên có khả năng xảy ra hiện tượng PSSS thay đổi. Chúng ta có thể dùng lệnh xttest3 ngay sau khi chạy lệnh xtreg, fe hoặc xtgls để biết được mô hình có bị hiện tượng PSSS thay đổi hay không. Lệnh này được phát triển dựa trên kiểm định Wald để kiểm tra sai số của mô hình hồi quy ảnh hưởng cố định (fixed effect model) thôi. Ad cũng chưa tìm hiểu được cách thức kiểm tra đối với mô hình OLS. Tuy nhiên, khi chạy hồi quy với dữ liệu bảng thì thông thường chúng ta nên chạy cả hai mô hình OLS và mô hình Fixed effect. Trên cơ sở đó, chúng ta có thể dùng lệnh xttest3 này để kiểm tra nhé.
Lệnh xttest3 này cũng ko có sẵn trong STATA mà chúng ta cần phải cài đặt trước khi sử dụng nhé. Giả thuyết H0 của kiểm định này tương tự như kiểm định BP hay White mà mình trình bày ở trên. Vậy nên, chúng ta cũng sẽ bác bỏ giả thuyết nếu như P-value < 0.1, nghĩa là mô hình có hiện tượng PSSS thay đổi.
5. Cách khắc phục
Vậy chúng ta sẽ khắc phục hiện tượng này như thế nào?
Cách 1: Chúng ta có thể dùng Weighted Least Squares (WLS). Về nguyên tắc, phương pháp hồi quy này được thực hiện tương tự như OLS, nhưng các giá trị quan sát được điều chỉnh/biến đổi (transform) bởi phương sai trước khi mô hình được ước lượng. Cái khó của phương pháp này đó là chúng ta phải thực hiện thử và sai nhiều lần để xác định được nên biến đổi các biến như thế nào.
Cách 2: Biến đổi biến về dạng log. Khi đó, thang đo biến sẽ nhỏ bớt lại và giúp làm giảm hiện tượng PSSS thay dổi. Ví dụ như khi 2 quan sát có giá trị là 8 và 80 được đưa về dạng log thì nó sẽ trở thành 2.0794 và 4.3280. Lúc này chênh lệch giữa các biến nhỏ hơn nhiều, nên hiện tượng PSSS thay đổi sẽ được hạn chế. Tuy nhiên, có 2 vấn đề cầu lưu ý: dạng log chỉ có giá trị với các quan sát lớn hơn 0 và hệ số beta lúc này phải được giải thích theo dạng thay đổi trong phần trăm.
Cách 3: Chúng ta có thể thực hiện winsorize để loại bỏ đi các outliers (nghĩa là loại bỏ đi các biến có giá trị bất thường). Để biết data của mình có outliers hay không thì các bạn có thể dùng lệnh summarize để truy xuất thông tin về giá trị trung bình, độ lệch chuẩn, giá trị lớn nhất và giá trị nhỏ nhất của biến nhé. Chúng ta có thể xem xét giá trị độ lệch chuẩn. Nếu như giá trị độ lệch chuẩn quá lớn thì nguy cơ cao là có outlier. Lúc này chúng ta có thể dùng lệnh winsor để loại bỏ đi các outlier này. Lệnh winsor không có sẵn trong STATA, nên các bạn cần phải cài đặt nó trước khi sử dụng nhé. Lệnh winsor không làm thay đổi số lượng quan sát, mà nó sẽ thay thế các giá trị outliers bằng các giá trị khác thôi. Ví dụ, mình muốn loại bỏ đi 1% giá trị nhỏ nhất và 1% giá trị lớn nhất trong dãy dữ liệu, thì lệnh winsor sẽ thay thế các giá trị này bằng giá trị nhỏ thứ 2% và lớn thứ 99%. Công thức sử dụng lệnh winsor như sau:
winsor bienA, gen(bienA_w) p(#) hoặc h(#)
Lệnh này giúp chúng ta winsor biến A và tạo ra biến A mới gọi là bienA_w, dựa trên việc kê khai giá trị p hoặc h.
Khi dùng p thì chúng ta kê khai % dữ liệu mà chúng ta muốn winsor. Số này bắt buộc phải nhỏ hơn 0.5 nhé. Nhưng 0.5 nghĩa là các bạn thực hiện winsor tới 50% số lượng quan sát rồi đó, như vậy là quá nhiều. Theo kinh nghiệm của ad thì các bạn nên thử với % nhỏ nhất như là 0.01 (nghĩa là 1%) và kiểm tra lại các giá trị thống kê mô tả.
Khi dùng h thì chúng ta kê khai số lượng quan sát mà mình muốn thay đổi ở mỗi đầu dữ liệu. Vậy nên h này nhận giá trị ít nhất là 1 quan sát và nhiều nhất là 1/2 quan sát trong bộ dữ liệu.
Nếu như bạn chỉ muốn điều chỉnh dữ liệu ở một trong hai đầu dữ liệu thì chúng ta có thể thêm lựa chọn highonly (cho giá trị lớn) hoặc là lowonly (cho giá trị nhỏ). Ví dụ như chúng ta thấy giá trị lớn nhất hoặc giá trị nhỏ nhất cách quá xa so với giá trị trung bình và vô lý thì chúng ta có thể dùng lựa chọn này nhé.
Cách 4: Ước lượng với phương sai sai số chuẩn (standard errors or robust standard errors)
Đối với cách này thì hệ số hồi quy của chúng ta vẫn như cũ, nhưng sai số của các hệ số hồi quy bây giờ sẽ được điều chỉnh để cho phép sự tồn tại của hiện tượng PSSS thay đổi và tất nhiên là đảm bảo giả định của mô hình hồi quy.
Để thực hiện thì khi chạy hồi quy, chúng ta chỉ cần thêm lựa chọn robust vào sau câu lệnh thôi.

Lúc này, nếu như mô hình không còn lỗi nào khác thì chúng ta có thể báo cáo kết quả này rồi. Tuy nhiên, phương pháp này yêu cầu mẫu dữ liệu lớn để thực hiện nhé.