Trong bài viết này, mình sẽ nói tất tần tật về một phương pháp hồi quy vô cùng kinh điển mà gần như ai học kinh tế lượng đều đã từng nghe qua và sử dụng. Đó là phương pháp hồi quy OLS – Ordinary Least Square. Chúng ta có thể dịch cụm từ này thành phương pháp hồi quy bình phương nhỏ nhất. Đây là phương pháp hồi quy được sử dụng phổ biến nhất trong nghiên cứu. Dù cho trong một vài trường hợp các phương pháp hồi quy khác được ưa chuộng hơn, kết quả hồi quy bằng OLS vẫn được xem là kết quả tiêu chuẩn (benchmark). Vậy bản chất của phương pháp này là gì?

Y và X được sử dụng để thể hiện cho tất cả quan sát của một tổng thể (population), còn y và x thể hiện cho các quan sát trong mẫu nghiên cứu được chọn (sample). Lưu ý vì chúng ta ko có đủ nguồn lực/chi phí để thu thập được toàn bộ dữ liệu của tổng thể, nên chúng ta chỉ có thể thu thập được một phần nhỏ của nó (mẫu dữ liệu) và tiến hành ước lượng các hệ số hồi quy trên mẫu thôi nhé. Lúc này các hệ số alpha và beta được ký hiệu với dấu mũ, thể hiện đây là các giá trị ước lượng.
Phương pháp OLS sẽ lựa chọn các hệ số hồi quy alpha và beta sao cho bình phương sai số của mô hình ước lượng là nhỏ nhất.

Như vậy, mục đích của phương pháp hồi quy OLS trở thành ước lượng alpha và beta sao cho S đạt giá trị nhỏ nhất.
Đến đây thì chúng ta lại quay trở về với việc giải bài toán tìm giá trị nhỏ nhất của hàm số S. Các bạn có còn nhớ cách giải bài toán này mà chúng ta đã học trong những năm cấp 3 ko nhỉ?
Bước 1: Chúng ta sẽ lấy đạo hàm bậc 1 của S lần lượt theo alpha mũ và beta mũ.
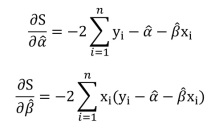
Bước 2: Chúng ta cho đạo hàm bằng 0 và tính alpha mũ và beta mũ theo x và y.
Công đoạn tính này khá phức tạp nên mình ko trình bày ở đây. Nếu các bạn quan tâm thì chúng ta có thể tìm thêm thông tin trên google nhé. Search theo cụm từ như là: Deriving Least Squares Estimators hoặc là Derivation of OLS coefficients.
Kết quả từ bước 2 sẽ giúp chúng ta tính được alpha mũ và beta mũ như sau:
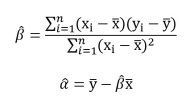
X ngang và y ngang là giá trị trung bình của x và y của mẫu nghiên cứu và n là tổng số quan sát trong mẫu nghiên cứu.
Các hệ số ước lượng alpha và beta mà các bạn có được khi chạy hồi quy OLS trong STATA sẽ được tính toán như vậy đấy.
Chạy mô hình hồi quy OLS trong STATA như thế nào?
Việc chạy mô hình OLS trong STATA vô cùng đơn giản, bằng cách sử dụng lệnh REGRESS (hoặc REG).
Trước khi chạy lệnh hồi quy, chúng ta cần phải set up dữ liệu trước – có nghĩa là chúng ta phải báo cho STATA biết dữ liệu mình đang dùng là dữ liệu theo thời gian (time-series), dữ liệu cắt ngang tại một thời điểm (cross-sectional) hay là dữ liệu bảng (panel data). Các bạn có thể xem lại bài viết về các dạng dữ liệu trong nghiên cứu tại đây nhé. Chúng ta sẽ không cần thực hiện bước này nếu dữ liệu đã ở dạng cross-sectional.
- Nếu là dữ liệu time-series, chúng ta cần dùng lệnh TSSET như sau:
tsset time_var
time_var là biến mô tả thời gian trong bộ dữ liệu.
- Nếu là dữ liệu panel, chúng ta cần dùng lệnh XTSET như sau:
xtset id_var time_var
id_var là biến chỉ các đối tượng quan sát trong bộ dữ liệu
Lưu ý: biến id_var cần phải là biến dạng số (numeric).
Nếu mẫu dữ liệu chưa có biến ID theo yêu cầu (có biến ID theo kiểu string) thì có thể dùng câu lệnh EGEN để tạo numerical ID nhé.
egen id=group(ID_stringvar)
ID_stringvar là biến ID thể hiện chứa dữ liệu tên công ty, tên quốc gia, tên thành phố, v.v…
Sau bước khai báo dữ liệu thì chúng ta có thể chạy hồi quy bằng lệnh REGRESS.
reg bienphuthuoc biendoclap1 biendoclap2 biendoclap3 …
Mình lấy hình ảnh minh hoạ kết quả chạy OLS từ hướng dẫn của STATA nhé.
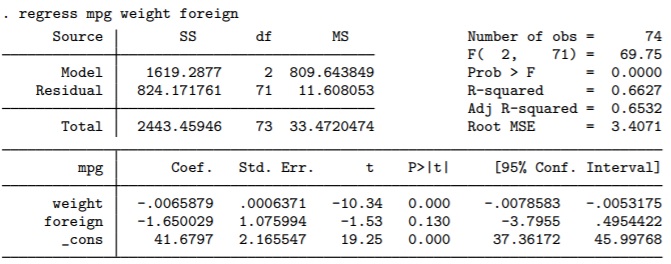
Theo mô hình này, chúng ta tìm mối quan hệ giữa biến phụ thuộc mpg (số cây số chạy được trên mỗi gallon xăng) và hai biến độc lập weight (cân nặng của xe), foreign (xe xuất sứ từ nước ngoài hay nội địa).
Thông thường, có 3 vấn đề mà chúng ta cần quan tâm đầu tiên: đó là hệ số hồi quy có ý nghĩa thống kê không, mô hình có ý nghĩa không và mức độ giải thích của mô hình như thế nào.
Đầu tiên kiểm định giả thuyết hệ số hồi quy. Chúng ta sẽ kiểm tra các hệ số hồi quy có ý nghĩa thống kê hay không?
Giả thuyết của chúng ta sẽ là beta = 0. Mục tiêu của chúng ta là bác bỏ giả thuyết này. Nghĩa là hệ số beta thực sự khác 0, và chúng ta có thể sử dụng hệ số beta ước lượng được để giải thích cho tác động của biến độc lập X lên sự biến động của biến phụ thuộc Y. Để thực hiện kiểm định này, chúng ta có thể sử dụng thống kê t hoặc thống kê z hoặc là giá trị P-value tương ứng.
Chúng ta thấy hệ số hồi quy của biến Weight là -0.0066 với P-value tương ứng là 0.000. Điều này có nghĩa là biến Weight có ảnh hưởng tiêu cực (có ý nghĩa thống kê) lên biến phụ thuộc. Hay nói cách khác xe càng nặng thì càng hao xăng.
Hệ số hồi quy của biến Foreign là -1.6500 với P-value tương ứng là 0.130. Giá trị P-value này lớn hơn 0.1 nên tác động của biến Foreign lên MPG không có ý nghĩa thống kê. Hay nói cách khác, dù là xe ngoại nhập hay xe nội địa, nếu có cùng các thông số kỹ thuật khác, thì mức độ hao xăng là như nhau.
Vấn đề thứ hai là kiểm định mô hình hay còn gọi là kiểm định F.
Giả thuyết cho kiểm định này là tất cả các hệ số hồi quy đồng thời bằng 0. Ví dụ beta 1 = beta 2 =….= beta k = 0. Nếu giả thuyết này KHÔNG BỊ bác bỏ thì cũng đồng nghĩa với việc mô hình KHÔNG CÓ ý nghĩa thống kê. Vậy nên chúng ta cũng mong muốn bác bỏ giả thuyết này. Để thực hiện kiểm định này chúng ta dùng thống kê F hoặc giá trị P-value tương ứng.
Theo bảng kết quả trên, ta thấy giá trị F được tính là 69.75 với P-value tương ứng là 0.000. Vậy nên, chúng ta có thể tạm thời yên tâm rằng mô hình này có ý nghĩa thống kê.
Cuối cùng, chúng ta kiểm tra giá trị của R-squared. R2 thể hiện cho % biến thiên của biến phụ thuộc được giải thích bởi mô hình. R2 thường nhận giá trị từ 0 đến 1.
Tuy nhiên, một vấn đề của R2 là khi càng đưa thêm biến độc lập vào mô hình, giá trị R2 càng tăng. Việc đưa thêm biến vào mô hình sẽ làm cho mô hình có khả năng bị sai dạng hàm hoặc gây ra các bệnh khác của mô hình. Vậy nên, chúng ta nên sử dụng R2 hiệu chỉnh. Trong kết quả minh họa, ta thấy R2 hiệu chỉnh có giá trị 65.32%.
Một câu hỏi mà chúng ta thường đặt ra là thế nào là một R-squared tốt. Câu trả lời cho câu hỏi này là it depends. Giá trị R2 tuỳ thuộc vào đối tượng nghiên cứu. Có những nghiên cứu, tác giả mong muốn hệ số R2 cần phải đạt đến 90% hoặc hơn, nhưng cũng có những nghiên cứu với R2 khoảng 10% đã được cho là tốt. Vậy nên, chúng ta nên tìm hiểu sâu hơn trong tổng quan nghiên cứu để dễ so sánh kết quả nghiên cứu của mình với những kết quả nghiên cứu đã có trước đó.