1. Định nghĩa:
Đây là hiện tượng mà sai số tại thời điểm t có mối quan hệ với sai số tại thời điểm t-1 hoặc tại bất kỳ thời điểm nào khác trong quá khứ. Ta ký hiệu sai số trong mô hình hồi quy là u nhé.
Đối với dữ liệu theo thời gian, hiện tượng này thường được gọi với tên trong tiếng Anh là “autocorrelation”. Tự tương quan bậc 1 (sai số kỳ t có tương quan với sai số kỳ t – 1) dưới dạng công thức như sau:
![]()
Đối với dữ liệu bảng, hiện tượng này thường được gọi với tên trong tiếng Anh là “serial correlation” và tự tương quan bậc 1 được diễn tả dưới dạng công thức như sau:
![]()
Lưu ý: Đây là mối quan hệ trong sai số giữa các khoảng thời gian khác nhau, nhưng với cùng một ID quan sát nhé.
Nếu có hiện tượng TTQ thì hệ số tương quan ρ sẽ khác 0, ngược lại nếu ρ = 0 thì chúng ta có thể yên tâm rồi.
2. Hậu quả:
Nếu mô hình có hiện tượng TTQ thì ước lượng bằng phương pháp OLS vẫn không bị thiên lệch (unbiased) và nhất quán (consistent). Tuy nhiên, các ước lượng này sẽ không còn là ước lượng hiệu quả nữa. Lưu ý, có thể có nhiều ước lượng cho một true beta, nhưng ước lượng hiệu quả nhất là ước lượng có sai số với true beta là nhỏ nhất. Bên cạnh đó, hiện tượng tự tương quan sẽ khiến cho giá trị t-value lớn hơn (hoặc P-value nhỏ hơn) so với giá trị mà nó nên có và làm cho hệ số hồi quy có xu hướng có ý nghĩa thống kê. Vô tình, chúng ta có thể kết luận một yếu tố nào đó của mô hình có ảnh hưởng đến biến phụ thuộc của mô hình, nhưng thực ra điều này bị gây ra bởi hiện tượng TTQ mà thôi. Nếu hiện tượng này xảy ra đồng thời với hiện tượng phương sai sai số thay đổi thì các ước lượng càng trở nên thiếu tin cậy thậm chí khi mẫu nghiên cứu của bạn lớn.
3. Các nhận biết:
Chúng ta có thể nhận biết hiện tượng này bằng cách plot (minh hoạ dữ liệu bằng biểu đồ) dữ liệu hoặc sử dụng các kiểm định nhé. Mình sẽ dùng bộ dữ liệu AIR2 của STATA để minh hoạ trong bài viết này. Bộ dữ liệu này gồm 3 biến – Biến air thể hiện số hành khách quốc tế, biến time thể hiện cho thời gian (tháng) từ năm 1949 đến năm 1960, biến t thể hiện cho các cột mốc thời gian. Bộ dữ liệu này có 144 quan sát nên t nhận giá trị từ 1 đến 144 nhé. Trong bộ dữ liệu này chỉ có dữ liệu về biến phụ thuộc mà ko có dữ liệu về các biến độc lập nào khác ngoài biến thời gian. Tuy nhiên, chúng ta hoàn toàn có thể kiểm tra được hiện tượng TTQ trong trường hợp này, bởi vì nếu biến phụ thuộc có hiện tượng TTQ thì sai số của mô hình với biến phụ thuộc đó (khả năng rất cao) là sẽ có hiện tượng TTQ. Để sử dụng bộ dữ liệu này thì chúng ta có thể gõ lệnh sau:
Cách 1: Plot dữ liệu
Như trong hai công thức mình trình bày ở trên, nếu sai số ở thời điểm t có mối quan hệ tuyến tính với sai số ở thời điểm t-1 thì nghĩa là có hiện tượng tự tương quan. Chúng ta sẽ lấy sai số này ra từ trong mô hình và sau đó thực hiện vẽ đồ thị để thể hiện mối quan hệ giữa sai số kỳ t và sai số kỳ t-1 nhé. Chúng ta có thể thực hiện các bước này trong STATA như sau:
tsset t // Lệnh này báo STATA biết đây là dữ liệu theo chuỗi thời gian
reg air t // Thực hiện hồi quy biến phụ thuộc trên biến chỉ thời gian
predict r, resid // Sai số (phần dư) của mô hình sẽ được lưu trong biến r nhé
twoway (scatter r l.r) (lfit r l.r) // theo lệnh này, mình sẽ thể hiện hiện tượng TTQ trong sai số bằng đồ thị scatter (các điểm dữ liệu của sai số sẽ được thể hiện bằng các dấu chấm trên khắp đồ thi) và bằng đường hồi quy tuyến tính (lfit – viết tắt của linear fit)
Đồ thị sẽ có dạng như sau:
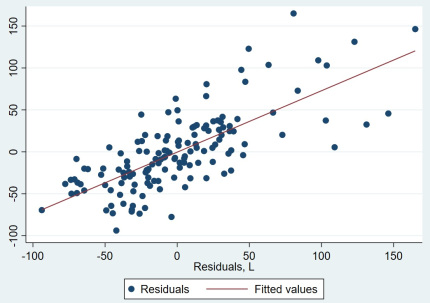
Trên đồ thị này, trục X thể hiện cho sai số tại thời điểm t-1 và trục Y thể hiện cho sai số tại thời điểm t. Ta có thể một cách rất rõ ràng rằng sai số giữa 2 thời kỳ có mối quan hệ tuyến tính với nhau. Chúng ta cũng có thể dùng lệnh CORR để tìm hệ số tương quan trong sai số bằng cách dùng lệnh:
corr r l.r // Kết quả là 0.7306
Như vậy, chúng ta có thể tự tin mà khẳng định rằng mô hình có hiện tượng TTQ.
Ta có thể kiểm tra hiện tượng TTQ ở các bậc khác nữa nhé. Ví dụ như TTQ bậc 2 thì ta sẽ plot giữa sai số kỳ t và sai số kỳ t-2 với câu lệnh sau:
twoway (scatter r l2.r) (lfit r l2.r)
Cách 2: Dùng các kiểm định
Ta cũng có thể dùng các kiểm định để kiểm tra xem hiện tượng tự tượng quan này có tồn tại không. Các kiểm định dùng cho time-series data và panel data có hơi khác một chút nha.
Đối với time-series data: Ta có thể dùng Durbin-Watson (DW) hoặc Breusch-Godfrey (BG)
Kiểm định DW chỉ có thể có ý nghĩa khi (1) mô hình hồi quy có hệ số chặn, (2) sai số có hiện tượng tự tương quan bậc 1 – nếu TTQ xuất hiện ở bậc khác thì kiểm định DW sẽ không phát hiện ra được đâu, (3) sai số tuân theo phân phối chuẩn (Mình sẽ nói về vấn đề này trong một bài viết khác nhé), và cuối cùng (4) biến độc lập trong mô hình không phải là biến lag của Y. Kiểm định DW sẽ cho ra hệ số thống kê d-statistic. Hệ số này được tính bằng công thức sau:
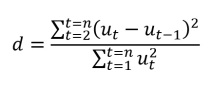
Hệ số d sẽ có giá trị nằm trong khoảng (0, 4). Có một số trường hợp có thể xảy ra với d như sau:
- Nếu d ≈ 0: Có TTQ dương
- Nếu d ≈ 4: Có TTQ âm
- Nếu d ≈ 2: Không có hiện tượng TTQ
Câu lệnh trong STATA cho DW sẽ là:
estat dwatson
Chúng ta phải chạy lệnh hồi quy trước rồi sau đó mới chạy lệnh này nhé.
Tuy nhiên, kiểm định DW có quá nhiều ràng buộc và hạn chế đúng không? Để tránh bớt các hạn chế này, chúng ta có thể dùng kiểm định BG để thay thế. Kiểm định BG có thể được thực hiện khi mô hình có bao gồm biến lag của biến phụ thuộc. Thông thường, việc dùng biến lag của biến phụ thuộc sẽ giúp kiểm soát được hiện tượng TTQ, nhưng nếu đó hiện tượng TTQ bậc cao thì việc dùng biến lag bậc 1 cũng không giúp ích được gì nhiều đâu. Thêm nữa, kiểm định BG cũng giúp kiểm tra được hiện tượng TTQ bậc cao.
Giả thuyết của kiểm định này là không có hiện tượng TTQ ở bất cứ bậc nào. Giả thuyết này có thể được viết như sau:
H0: ρ1 = ρ2 = ρ3 = … = ρn = 0
Để kết luận mô hình không có hiện tượng TTQ, chúng ta kỳ vọng không bác bỏ giả thuyết này, nghĩa là giá trị P-value càng lớn càng tốt – ít nhất là cần phải lớn hơn 0.1 nhé. Kiểm định này được thực hiện trong STATA bằng lệnh sau:
estat bgodfrey, lags(#)
Chúng ta kê khai giá trị lag mà chúng ta muốn kiểm định nhé. Ví dụ như lags(3) thì có nghĩa mô hình sẽ kiểm tra TTQ bậc 1, bậc 2 và bậc 3. Nếu chúng ta không kê khai thì mô hình chỉ kiểm định TTQ bậc 1 thôi nhé.

Đây là kết quả kiểm định DW và BG cho mô hình ở trên. Ta có thể thấy là cả 2 kiểm định đều khẳng định rằng mô hình có hiện tượng TTQ và đây là TTQ dương.
Đối với panel data: Ta có thể dùng kiểm định Wooldridge. Kiểm định này cũng đặt ra giả thuyết tương tự như kiểm định BG – đó là mô hình không có hiện tượng tự tương quan. Vì vậy, chúng ta sẽ kỳ vọng thấy được giá trị P-value lớn hơn 0.1.
Đây không phải là một lệnh có sẵn trong STATA, nên chúng ta cần cài đặt trước khi sử dụng nhé.
ssc install xtserial
xtserial y x1 x2 x3
4. Cách khắc phục:
Chúng ta có thể biến đổi mô hình để loại bỏ hiện tượng TTQ, sử dụng phương pháp Newey-West để chỉnh sửa sai số ước lượng hoặc đưa biến trễ (lag) của biến phụ thuộc vào mô hình. Mình sẽ làm rõ từng trường hợp nhé.
Cách 1: Biến đổi theo sai phân bậc nhất (first-difference transformation)
Ta sẽ đưa tất cả dữ liệu về dạng sai phân bậc một – nghĩa là lấy hiệu số giữa quan sát kỳ t và quan sát kỳ t-1 cho từng biến trong mô hình. Theo cách này, ta đang giả định hệ số tương quan ρ = 1. Thay vì ước lượng mô hình như bình thường (gọi là level form), ta sẽ ước lượng mô hình với dữ liệu đã được biến đổi như sau:
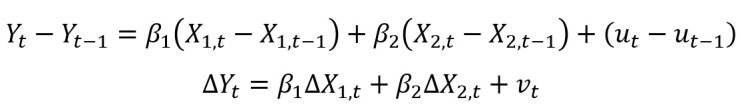
Lúc này, sai số của mô hình đã được biến đổi nên hiện tượng TTQ cũng bị loại bỏ. Khi ước lượng mô hình sai phân bậc nhất này, chúng ta cần lưu ý mô hình không có hệ số chặn. Lệnh STATA ta có thể dùng như sau:
reg d.Y d.X1 d.X2 dX3, noconstant
Bạn không cần phải tao biến lag, rồi lấy hiệu số để tính ra sai phân bậc 1 của các biến nha. Chỉ cần dùng d. ở phía trước các biến thì STATA sẽ tự động tạo dữ liệu sai phân bậc 1 cho bạn nè.
Cách 2: Biến đổi theo hệ số tương quan ước lượng (generalized transformation)
Theo cách này, ta sẽ biến đổi dữ liệu theo ước lượng hệ số tương quan ρ. Trước tiên, ta sẽ chạy hồi quy với dữ liệu ban đầu và lấy ra các sai số. Sau đó, ta sẽ chạy mô hình hồi quy giữa sai số kỳ t và sai số kỳ t-1 để lấy ra ước lượng của ρ. Và cuối cùng ta sẽ dùng hệ số ρ đó để biến đổi dữ liệu. Ví dụ, biến Y_new = Yt – ρ*Yt-1.
Mô hình hồi quy bây giờ sẽ trở thành Y_new = X1_new X2_new…
Trong STATA, ta có thể thực hiện các bước này như sau:
regress Y X1 X2 X3
predict r, resid // sai số được lưu trong biến r
reg r l.r, nocons // ρ sẽ là hệ số hồi quy đứng trước biến lag của r. Giả sử ρ = 0.7
gen Y_new = Y – 0.7*l.Y // ký hiệu l.Y nghĩa là lag bậc 1 của biến Y
gen X1_new = X1 – 0.7*l.X1
gen X2_new = X2 – 0.7*l.X2
reg Y_new X1_new X2_new
Ngoài ra, ta cũng có thể sử dụng thống kê d-statistic có được từ kiểm định Durbin-Watson để tính ra hệ số ρ này: ρ ≈ 1 – d/2
Cả 2 cách mà mình giới thiệu ở trên chỉ sử dụng khi dữ liệu chỉ có hiện tượng tự tương quan bậc 1. Nếu dữ liệu có hiện tượng TTQ bậc cao hơn, chúng ta cần phải biến đổi dữ liệu theo các hệ số tương quan ở bậc cao hơn. Lúc này, sai số tại kỳ t sẽ không chỉ có mối quan hệ với sai số kỳ t-1 mà còn có mối quan hệ với sai số kỳ t-2 hoặc các kỳ trước đó nữa. Ví dụ:
![]()
Ta cần phải ước lượng cả ρ1 và ρ2 và dùng nó đểu biến đổi dữ liệu nhé. Trong trường hợp có hiện tượng TTQ bậc cao, ta cũng có thể sử dụng mô hình ARIMA để ước lượng.
Cách 3: Sử dụng phương pháp Newey-West để chỉnh sửa sai số ước lượng
Theo cách này, hệ số hồi quy beta vẫn được tính như bình thường, nhưng sai số sẽ được điều chỉnh theo cả hai hiện tượng phương sai sai số thay đổi và tự tương quan. Tuy nhiên, cách này chỉ nên được sử dụng khi mẫu dữ liệu lớn nhé. Trong STATA, ta có thể thực hiện phương pháp này bằng cách dùng một trong hai lệnh sau:
reg Y X1 X2 X3, vce(robust)
newey Y X1 X2 X3, lag(#)
Nếu dùng câu lệnh newey, chúng ta phải kê khai bậc cho biến lag nhé – giá trị nhỏ nhất là 1 thể hiện dự đoán trong dữ liệu chỉ có hiện tượng TTQ bậc 1.
Cách 4: Đưa biến trễ (lag) của biến phụ thuộc vào mô hình
Một trong những nguyên nhân của hiện tượng TTQ là do biến phụ thuộc có hiện tượng TTQ – quan sát biến Y kỳ t có mối quan hệ với quan sát biến Y kỳ t-1. Vậy nên, ta cũng có thể đưa biến trễ của biến Y vào trong mô hình để kiểm soát hiện tượng này.
reg Y l.Y X1 X2 X3 // Nếu chỉ muốn đưa biến lag bậc 1 của Y vào mô hình
reg Y l(1/2).Y X1 X2 X3 // Nếu muốn đưa cả lag bậc 1 và bậc 2 của biến Y vào mô hình
Sau khi sửa lỗi thì chúng ta nhớ dùng các kiểm định DW, BG hoặc Wooldrige mà mình trình bày ở trên để kiểm tra lại nhé. Lưu ý, các kiểm định này sẽ không có hiệu quả khi mình đã sửa lỗi bằng cách thứ 3 và kiểm định DW cũng sẽ không thực hiện được khi chúng ta đã sửa lỗi theo cách thứ 4.
Tóm lại, nếu dữ liệu của bạn là dữ liệu có yếu tố thời gian, bạn cần phải hết sức lưu ý đến hiện tượng TTQ. Khi hiện tượng này xảy ra, các sai số ước lượng của mô hình hầu hết sẽ bị “thồi phồng” lên, làm cho giá trị t-value lớn hơn cũng như P-value nhỏ hơn. Theo đó, bạn sẽ có xu hướng kết luận một hệ số hồi quy nào đó có ý nghĩa thống kê, nhưng thực ra kết quả này bị gây ra do hiện tượng TTQ mà thôi.
Thêm một lưu ý nhỏ nữa mình muốn đề cập trước khi kết thúc bài viết này – liên quan đến cách sửa lỗi thứ 4. Nếu sau khi đưa biến trễ của Y vào mô hình và dùng kiểm định BG để kiểm tra lại mà hiện tượng TTQ vẫn còn tồn tại, các hệ số hồi quy lúc này có thể bị thiên lệch (biased) và không nhất quán (inconsistent). Như vậy, hiện tượng TTQ đã bị gây ra vì các nguyên nhân khác như là sai dạng hàm. Lúc này, ta cần phải sử dụng các phương pháp khác như là phương pháp biến công cụ (instrument variable) để xử lý vấn đề này vì phương pháp OLS sẽ không còn hiệu quả nữa.
Vậy nên, các cách kiểm tra và sửa lỗi hiện tượng TTQ trên đây chỉ có tác dụng khi giả định mô hình nghiên cứu là hợp lý (correctly specified model) được thỏa mãn. Đây cũng là một trong những vấn đề của mô hình hồi quy khó xử lý nhất. Mình sẽ giới thiệu với các bạn vấn đề này trong bài viết lần sau.