Trong STATA, để ghép nối các dữ liệu với nhau, ta có thể dùng lệnh MERGE hoặc APPEND. Lệnh MERGE thì thường dùng để kết nối dữ liệu theo chiều ngang, còn lệnh APPEND thì thường dùng để kết nối dữ liệu theo chiều dọc. Để dễ hình dung hơn thì các bạn xem hình vẽ dưới đây nhé:
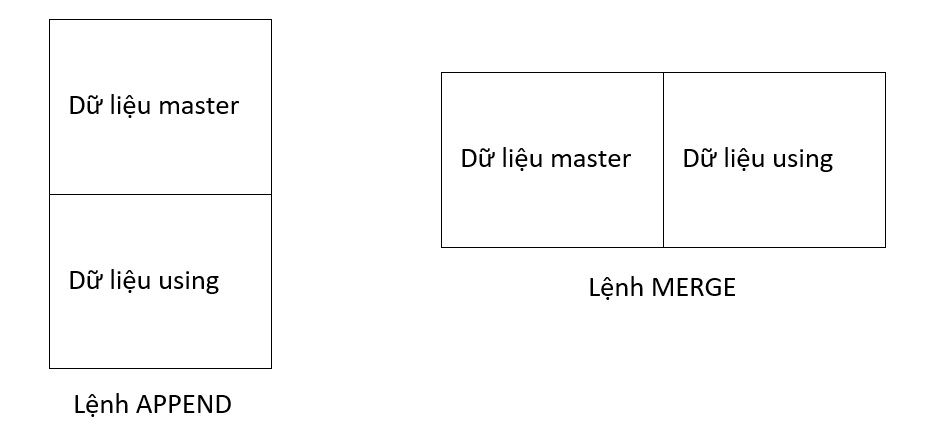
Tại một thời điểm thì STATA chỉ có thể hiển thị một bộ dữ liệu. Bộ dữ liệu đang được hiển thị, đang được sử dụng được gọi là dữ liệu master. Bộ dữ liệu bạn muốn ghép nối vào được gọi là dữ liệu using. Lệnh APPEND sẽ kết nối dữ liệu dựa trên tên biến, còn lệnh MERGE thì kết nối dữ liệu dựa trên giá trị của biến. Mình sẽ giải thích cụ thể từng lệnh nhé.
Lệnh APPEND
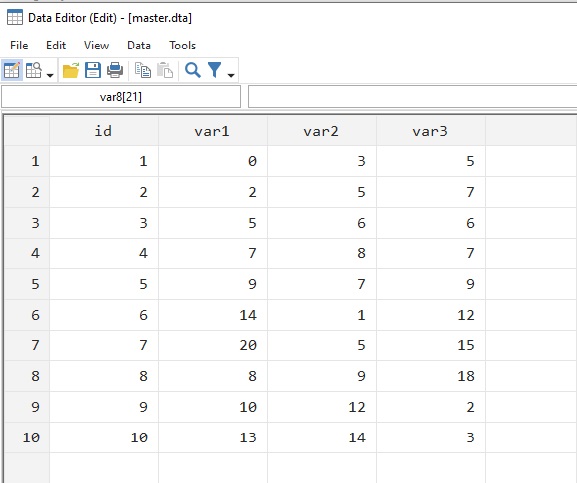
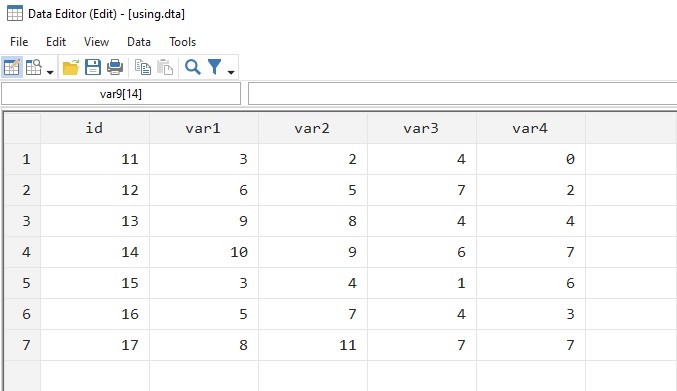
Giả sử mình có dữ liệu master và using như hình minh họa bên dưới. Hai bộ dữ liệu này có chung biến id. Bộ dữ liệu master có id từ 1 đến 10, còn bộ dữ liệu using có id từ 11 đến 17. Đường dẫn đến 2 bộ dữ liệu này như sau:
Master: C:\How to STATA\master.dta
Using: C:\How to STATA\using.dta
Mình muốn ghép nối hai bộ dữ liệu này vô chung một bộ dữ liệu. Mình sẽ dùng lệnh như sau:
use “C:\How to STATA\master.dta”, clear /*lệnh này để chắc chắn bộ dữ liệu đang sử dụng chính là master*/
append using “C:\How to STATA\using.dta”
Kết quả bộ dữ liệu mới của chúng ta sẽ như thế này:
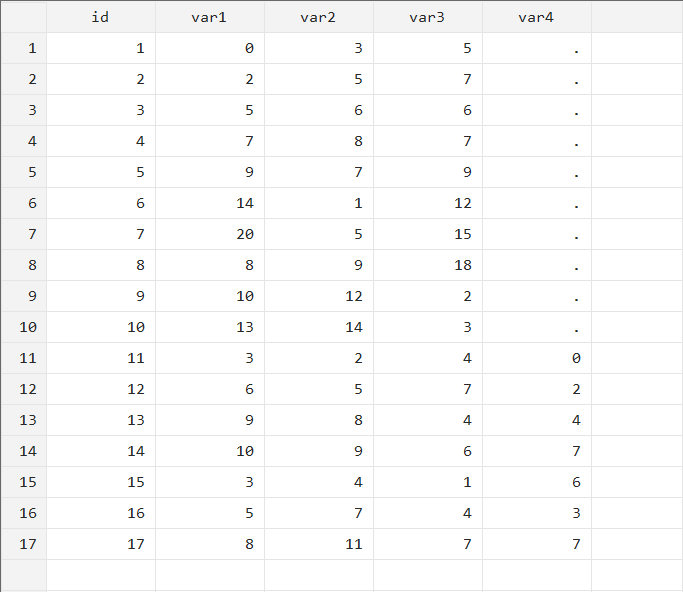
Khi sử dụng lệnh append, chúng ta có thể thêm một số lựa chọn sau:
append using “C:\How to STATA\using.dta”, gen(matching)
Khi thêm lựa chọn này nghĩa là ta tạo ra thêm một biến trong bộ dữ liệu, ad tạm đặt tên là matching. Biến matching này sẽ nhận giá trị 0 nếu các giá trị trong hàng tương ứng đều là dữ liệu từ bộ dữ liệu master, và nhận giá trị 1 nếu các giá trị trong hàng tương ứng là dữ liệu đến từ bộ dữ liệu using. Việc thêm biến này giúp chúng ta dễ kiểm tra lại nguồn dữ liệu.
append using “C:\How to STATA\using.dta”, keep(id var1 var2 var3)
Với lựa chọn keep này thì chúng ta có thể đưa vào trong dấu ngoặc đơn các biến của bộ dữ liệu using mà chúng ta muốn ghép nối vào bộ dữ liệu master. Như trong ví dụ của mình thì bộ dữ liệu master có biến id, var1, var2, var3; còn bộ dữ liệu using có biến id, var1, var2, var3, var4. Nếu ta chỉ muốn ghép dữ liệu của id, var1, var2, var3 từ bộ dữ liệu using vào bộ master thì ta có thể thêm vào câu lệnh keep(id var1 var2 var3) như trên.
append using “C:\How to STATA\using.dta”, force
Nếu chúng ta thêm force vào sau câu lệnh thì nghĩa là chúng ta bắt buộc STATA ghép nối biến có định dạng khác nhau. Ví dụ: ở bộ dữ liệu master có biến var5 là biến có định dạng chuỗi. Biến var5 cũng xuất hiện ở bộ dữ liệu using nhưng có định dạng số. Nếu như ta chỉ dùng câu lệnh thông thường thì STATA sẽ báo lỗi r(106). Ta có thể thêm vào câu lệnh lựa chọn force để lệnh append được tiến hành bình thường. Tuy nhiên, các dữ liệu trong biến var5 của bộ dữ liệu using sẽ bị biến bất khi dùng lệnh append. Vậy nên, trước khi sử dụng lệnh append, chúng ta nên kiểm tra định dạng của các biến trước nhé. Các biến cùng tên thì nên chuyển về cùng một dạng định dạng – cùng là dạng chuỗi hoặc cùng là dạng số.
Lệnh MERGE
Như mình nói ở trên, lệnh merge sẽ ghép nối dữ liệu bằng việc so sánh giá trị hoặc vị trí của dữ liệu. Mình cũng giả định có 2 bộ dữ liệu mang tên master và using trong trường hợp này nhé. Có rất nhiều lựa chọn ghép nối theo lệnh merge bao gồm one-to-one (1:1), many-to-one (m:1), one-to-many (1:m), many-to-many (m:m), one-to-one _n (1:1 _n). Trong đó, lựa chọn ghép nối m:1 và 1:m là phổ biến nhất. Lựa chọn m:m và 1:1 _n sẽ cho ra kết quả ghép nối theo thứ tự của dữ liệu (dữ liệu hàng số 1 của master nối với dữ liệu hàng số 1 của using). Hai kiểu ghép nối này chúng ta không nên sử dụng nhé vì kết quả ghép nối dễ bị sai sót. Trong bài viết này mình giới thiệu với các bạn 3 kiểu ghép nối đầu tiên thôi nhé đó là 1:1, m:1 và 1:m.
Trước tiên, mình có một số lưu ý khi sử dụng lệnh MERGE:
– Lệnh merge không yêu cầu phải sắp xếp (sort) dữ liệu trước, vì khi dùng lệnh này thì STATA sẽ ngầm thực hiện bước sắp xếp này, sau đó mới đến bước sáp nhập dữ liệu (merge.) Tuy nhiên, nếu dữ liệu không được sắp xếp trước, thời gian STATA xử lý lệnh MERGE sẽ khá lâu và tốn bộ nhớ RAM của máy tính nữa. Vậy nên, tốt hơn hết là chúng ta nên sort dữ liệu trước khi dùng lệnh MERGE nhé.
– Lệnh MERGE sẽ tự động tạo ra biến với tên gọi là _merge để thông báo cho chúng ta biết có bao nhiêu dữ liệu được ghép nối và bao nhiêu dữ liệu không được ghép nối. Biến này có giá trị 1 nếu như quan sát chỉ xuất hiện ở bộ dữ liệu master, giá trị 2 nếu như quan sát chỉ xuất hiện ở bộ dữ liệu using và giá trị 3 nếu như quan sát xuất hiện ở cả 2 bộ dữ liệu.
Cụ thể về từng trường hợp khi dùng lệnh MERGE như sau:
Kiểu 1:1 (1 dữ liệu trong master ghép với 1 dữ liệu trong using dựa theo một hoặc nhiều biến chung)
Giả sử mình có dữ liệu khám sức khỏe như sau: Bộ dữ liệu mang tên cân nặng bao gồm các biến id, giới tính, cân nặng, chiều cao; bộ dữ liệu mang tên huyết áp bao gồm các biến id, huyết áp, nhịp tim.
Đường dẫn đến hai bộ dữ liệu này như sau:
Master: C:\How to STATA\cannang.dta
Using: C:\How to STATA\huyetap.dta

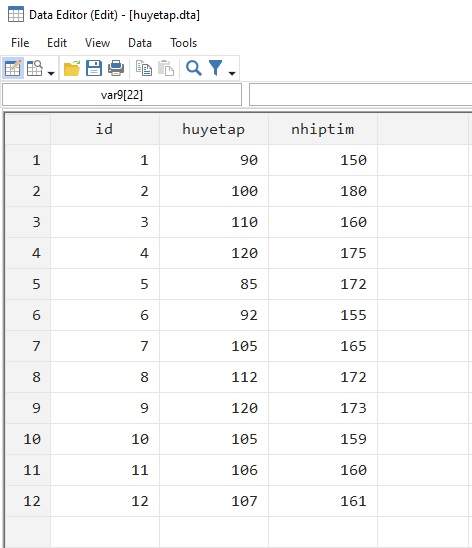
Chúng ta sẽ sáp nhập 2 bộ dữ liệu này vào với nhau dựa trên biến id. Lệnh MERGE được viết như sau:
use “C:\How to STATA\huyetap.dta” /*Lệnh này để gọi bộ dữ liệu huyết áp – dữ liệu using*/
sort id /*sắp xếp dữ liệu huyết áp theo thứ tự ID tăng dần*/
use “C:\How to STATA\cannang.dta” /*Lệnh này để gọi bộ dữ liệu cân nặng – dữ liệu master*/
sort id /*sắp xếp dữ liệu cân nặng theo thứ tự ID tăng dần*/
merge 1:1 id using “C:\How to STATA\huyetap.dta” /*sáp nhập 2 bộ dữ liệu lại với nhau*/
Như vậy, cột huyết áp và nhịp tim của bộ dữ liệu using sẽ được sáp nhập vào bộ dữ liệu master. Kết quả bộ dữ liệu mới như sau:
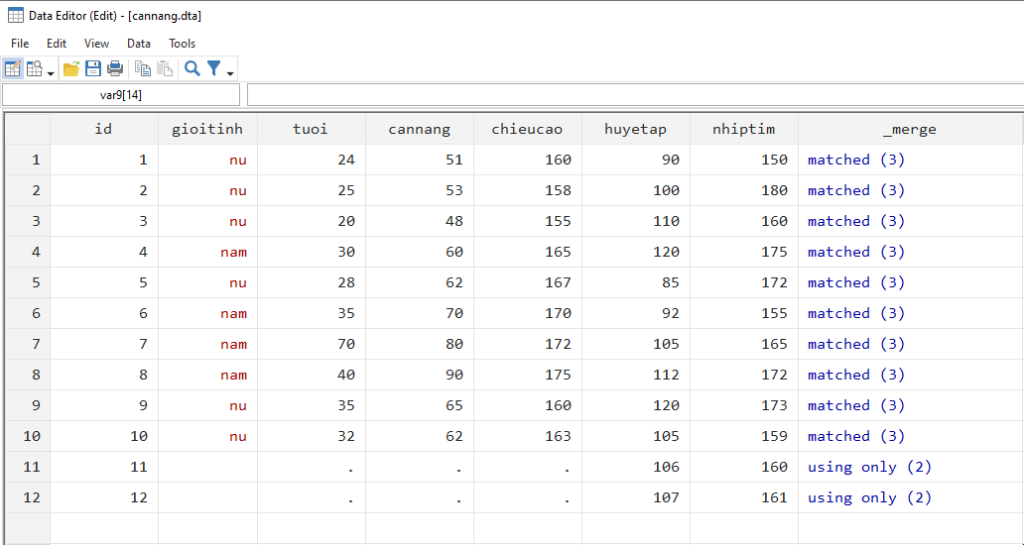
Ta thấy rằng biến _merge được tự động hình thành và cho chúng ta biết các giá trị nào được sáp nhập và giá trị nào không. Trong trường hợp này 10 dòng dữ liệu đầu đều khớp về giá trị ID giữa hai bộ dữ liệu, còn 2 dòng dữ liệu cuối cùng, tương ứng với ID 11 và 12 thì chỉ có dữ liệu trong bộ dữ liệu using mà thôi. Sau khi chạy câu lệnh trên, ta sẽ nhận được thông báo như sau:

Số dữ liệu trùng khớp (matched) về ID là 10; số dữ liệu không trùng khớp (not matched) là 2. Trong đó từ bộ master là 0 và từ bộ using là 2. Nếu chúng ta muốn loại bỏ đi các dòng dữ liệu không trùng khớp thì chỉ cần dùng lệnh drop if như sau:
drop if _merge != 3 /*loại bỏ đi các quan sát khi _merge khác 3 – nghĩa là các dữ liệu không trùng khớp về ID*/
Kiểu one-to-many 1:m (1 dữ liệu trong master ghép nối với nhiều dữ liệu trong using)
Ví dụ để chúng ta dễ hình dung kiểu dữ liệu này là: chúng ta có bộ dữ liệu về kinh tế vĩ mô như tỷ lệ lạm phát, tỷ lệ thất nghiệp theo từng năm và bộ dữ liệu về tình hình tăng trưởng của các doanh nghiệp theo năm. Chúng ta muốn ghép nối các dữ liệu kinh tế vĩ mô vào dữ liệu của doanh nghiệp để có thể đưa biến vĩ mô vào mô hình hồi quy của mình. Minh họa 2 bộ dữ liệu này như sau nhé:
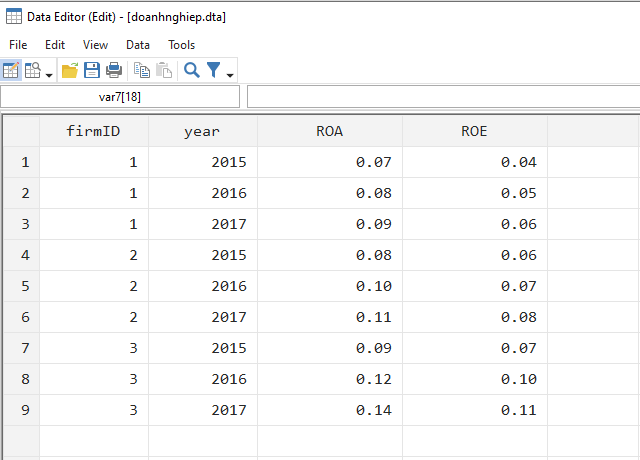
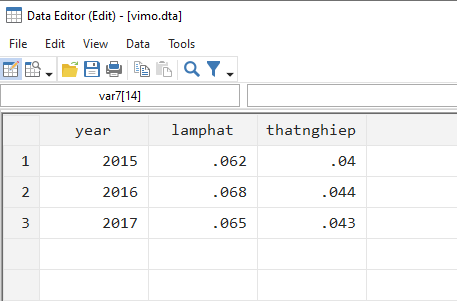
Đối với kiểu sáp nhập 1:m này thì dữ liệu vĩ mô sẽ là dữ liệu master (1), còn dữ liệu doanh nghiệp là dữ liệu using (m). Điểm chung giữa hai bộ dữ liệu này là biến year. Để merge hai dữ liệu này với nhau, ta lần lượt dùng các lệnh sau:
use “C:\How to STATA\doanhnghiep.dta” /*gọi bộ dữ liệu using ra trước*/
sort year /*sắp xếp dữ liệu theo biến chung (year). Nếu có nhiều hơn 1 biến chung thì chúng ta sort dữ liệu theo các biến chung mà bạn muốn đối chiếu giữa hai bộ dữ liệu và sort theo thứ tự ưu tiên sắp xếp*/
use “C:\How to STATA\vimo.dta” /*gọi bộ dữ liệu master*/
sort year /*sắp xếp dữ liệu master theo năm*/
merge 1:m year using “C:\How to STATA\doanhnghiep.dta” /*sáp nhập hai dữ liệu với nhau theo biến year*/
Đây là kết quả sáp nhập dữ liệu:
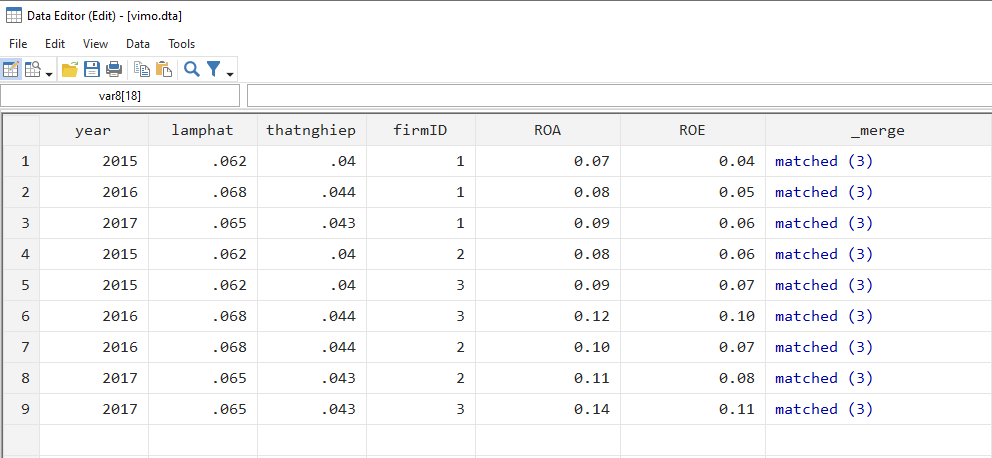
Kiểu many-to-one m:1 (nhiều dữ liệu trong master ghép nối với 1 dữ liệu trong using)
Ngược lại, đối với kiểu sáp nhập m:1, dữ liệu master bây giờ sẽ là bộ dữ liệu doanh nghiệp có nhiều hơn một quan sát có số năm như nhau và dữ liệu using là bộ dữ liệu vĩ mô khi mỗi năm chỉ có 1 quan sát. Để sáp nhập dữ liệu, ta sẽ lần lượt thực hiện các lệnh sau:
use “C:\How to STATA\vimo.dta”
sort year
use “C:\How to STATA\doanhnghiep.dta”
sort year
merge m:1 year using “C:\How to STATA\vimo.dta”
Bộ dữ liệu sau sáp nhập sẽ hoàn toàn giống với ở trên.
Ví dụ khi sáp nhập theo 2 biến chung
Giả sử ta có dữ liệu master và using như sau:
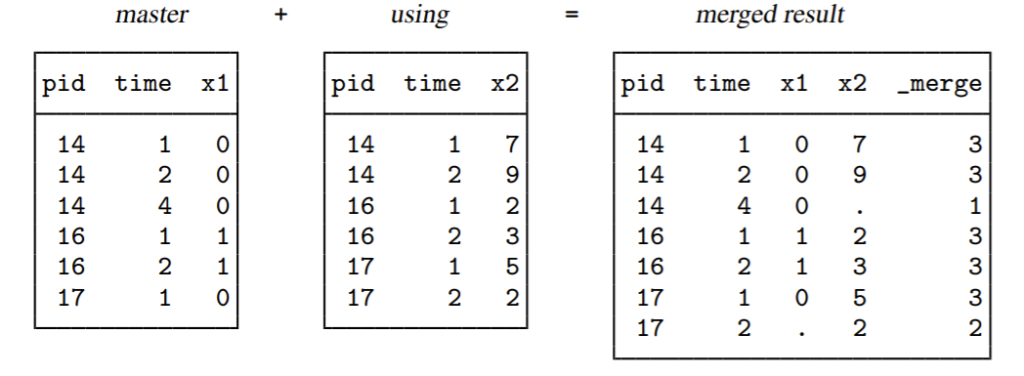
Hai bộ dữ liệu này có 2 biến chung đó là pid và time. Trong trường hợp này, ta thấy ở cả 2 bộ dữ liệu, mỗi giá trị pid và time đều có nhiều hơn 1 quan sát. Vì vậy, chúng ta có thể dùng kiểu sáp nhập 1:1. Công thức lệnh như sau:
use “C:\How to STATA\master.dta”
merge 1:1 pid time using “C:\How to STATA\using.dta”
Tóm lại, khi sử dụng lệnh merge, chúng ta cần xem kiểm tra các vấn đề sau:
- Biến chung là biến nào?
- Số quan sát liên quan đến biến chung có lặp lại trong 2 bộ dữ liệu hay không? Nếu số quan sát nhiều hơn 1 ở cả 2 bộ dữ liệu thì ta sẽ dùng kiểu sáp nhập 1:1. Nếu một bộ quan sát có sự lặp lại quan sát của biến chung, bộ còn lại thì không thì chúng ta có thể dùng 1:m hoặc m:1. Chúng ta có thể tùy chọn bộ dữ liệu master và using.
- Nên sort dữ liệu theo biến chung trước khi dùng lệnh merge
- Gọi và sort bộ dữ liệu using trước rồi mới đến bộ dữ liệu master.
- Có thể loại bỏ các dòng dữ liệu không trùng khớp bằng việc loại bỏ đi các quan sát khi _merge không bằng 3 (bằng 1 hoặc 2).