Hôm nay chúng ta sẽ bàn về “Các sai số đặc trưng trong mô hình”. Khi nói đến khái niệm này chúng ta phải nhớ ngay đến 4 vấn đền sau đây nha:
- Bỏ sót biến cấn thiết
- Thừa biến không liên quan
- Sai dạng hàm
- Sai số đo lường
Điểm sơ qua lý thuyết 1 tý nhé. Tất cả các sai phạm và nhiều vấn đề liên quan khác đều có ảnh hưởng chéo lên nhau và dẫn đến hiện tượng hồi quy giả mạo, kết quả mô hình bị lệch. Ví dụ chúng ta bỏ sót biến nghiên cứu sẽ dẫn đến tính toán phương sai không chính xác khi ước lượng. Trường hợp biến bị loại có tương quan với các biến còn lại trong mô hình sẽ dẫn tới kết quả mô hình bị lệch và không nhất quán hoặc nếu không tương quan với các biến trong mô hình thì hệ số chặn sẽ bị lệch và lệch giá trị dự báo. Việc bỏ sót biến cần thiết cũng sẽ làm sai lệch hệ số các biến còn lại trong mô hình kéo theo các kết luận sai khi phân tích.
Nói lý thuyết màu mè vậy thôi. Nếu nói kỹ thì không biết bao giờ mới hết. Chúng ta rất khó để nói rằng biến X trong mô hình là biến thừa hay biến A là biến thiếu nên chỉ có một kênh uy tín nhất để giải quyết vấn đề này là cơ sở lý thuyết và cơ sở lý luận. Khi đã tương đối chắc chắn về mô hình nghiên cứu, chúng ta sẽ xét một số ý tiền đề trước khi đi sâu vào xử lý các sai phạm.
Trước mắt hãy kiểm tra R2 và các kiểm định t của các hệ số, kiểm định ANOVA (kiểm định F của mô hình), hệ số Durbin-Watson và đồ thị phần dư. Tuy nhiên hôm nay chúng ta không nói kỹ về những vấn đề này. Những phần tiếp theo ad sẽ đề cập đến.
Phần quan trọng tiếp theo, một trong những kiểm định khá nổi tiếng để kiểm tra các sai số đặc trưng đó là kiểm định RESET của Ramsay (1969). Điểm sơ qua về kiểm định này thì mục đích sinh ra là để kiểm tra xem mô hình có bỏ qua biến nghiên cứu nào không những biến này gọi là omitted variables. Tuy nhiên, theo nhiều tài liệu tại Việt Nam, kiểm định này đã được suy rộng và trả lời cho câu hỏi mô hình nghiên cứu có đúng hay không? Hay nói cách khác có tồn tại các sai số đặc trưng trong mô hình hay không? (Đinh Công Khải, 2011). Trong STATA hỗ trợ cho chung ta hàng tá phương pháp để tính toán kiểm định này.
Cơ bản nhất chúng ta có estat ovtest Nâng cao hơn thì có ramsey, reset, reset2 và có 2 trường hợp đặc biệt là ivreset dành co IV, resetxt dành cho dữ liệu bảng. Vẫn là kể mang tính màu mè vậy thôi nha. Dành cho các bạn nào có nhu cầu muốn tìm hiểu kinh tế lượng nâng cao là như thế nào. Ở đây chúng ta chỉ bàn về estat ovtest thôi nhé. Quay trở lại với file dữ liệu ở phần 1 tại [https://docs.google.com/spreadsheets/d/1I7ZlEWhI_dVBICuRdnYn3YuCAQjDcEovjDdB0yDOP_8/edit#gid=855741578] [Đây] nha. Chúng ta sẽ bắt đầu chạy lại mô hình ở phần 1 qua câu lệnh reg.
reg Y X1 X2 X3 X4 X5 và kết quả như sau:
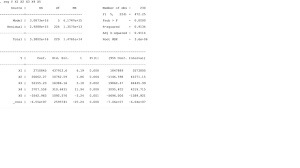
Kết đế chạy lệnh estat ovtest và kết quả như sau:

Kết quả Prob > F bé hơn 0.05 tức kiểm định có ý nghĩa ở mức 5% vậy chúng ta sẽ kết luận là có cơ sở bác bỏ giả thuyết mô hình Y là đúng hoặc tồn tại các sai số đặc trưng trong mô hình Y hoặc mô hình Y đã bỏ sót các biến quan trọng. Các bạn thắc mắc tại sao lại có tận 3 cách giải thích khác nhau hãy đọc lại đoạn đầu 1 tý vì chúng ta có đến 2 quan điểm nghiên cứu lận nhé.
Mở rộng của câu lệnh này là rhs khi các biến giải thích được thêm vào kiểm định thay cho các giá trị ước tính (fitted values) trước đó.

À, kết quả vẫn tương tự như trên khi Prob > F vẫn bé hơn 0.05.
Vậy kết luận của chúng ta là mô hình này sai rồi.