Kinh tế lượng dữ liệu bảng (panel data) hiện đại bao gồm một hệ thống các bộ ước lượng đa dạng, được thiết kế nhằm xử lý các dạng vi phạm khác nhau đối với các giả định cổ điển. Sai lầm phổ biến trong nghiên cứu thực nghiệm là xem phân tích dữ liệu bảng chỉ đơn thuần là lựa chọn giữa mô hình tác động cố định (Fixed Effects – FE) và tác động ngẫu nhiên (Random Effects – RE). Do đó, nhiệm vụ trung tâm của nhà nghiên cứu không phải là chọn trực tiếp một mô hình, mà là xác định đặc điểm của quá trình sinh dữ liệu (data-generating process – DGP), sau đó lựa chọn bộ ước lượng có giả định phù hợp nhất với các đặc điểm đó.
Kinh tế lượng dữ liệu bảng phát triển mạnh mẽ trong ba thập kỷ qua xuất phát từ thực tế dữ liệu kinh tế hiếm khi thỏa mãn đầy đủ các giả định truyền thống. Các đơn vị chéo thường chịu tác động từ các cú sốc chung, chuỗi thời gian có thể mang tính không dừng, hệ số hồi quy có thể khác nhau giữa các đơn vị, và biến giải thích thường mang tính nội sinh. Vì vậy, lựa chọn mô hình nên được hiểu như một quá trình loại dần các bộ ước lượng không phù hợp, thay vì tìm kiếm một kỹ thuật “tối ưu duy nhất”.
Theo cách tiếp cận này, phân tích dữ liệu bảng được triển khai theo chuỗi câu hỏi có tính phân tầng: quan sát có độc lập chéo hay không; biến có dừng hay không; có tồn tại quan hệ cân bằng dài hạn hay không; hệ số có đồng nhất giữa các đơn vị hay không; và có hiện tượng nội sinh hay không. Câu trả lời cho các câu hỏi này dần thu hẹp tập mô hình khả dĩ.
Bảng sau đây tổng hợp một cách tương đối (xem kết hợp hình dưới) các mô hình và quy trình phân tích dữ liệu bảng (panel data) phát triển đến hiện tại. Để có thể triển khai được cần các kiến thức về kinh tế lượng và sử dụng phần mềm phân tích thống kê tham khảo tại đây.
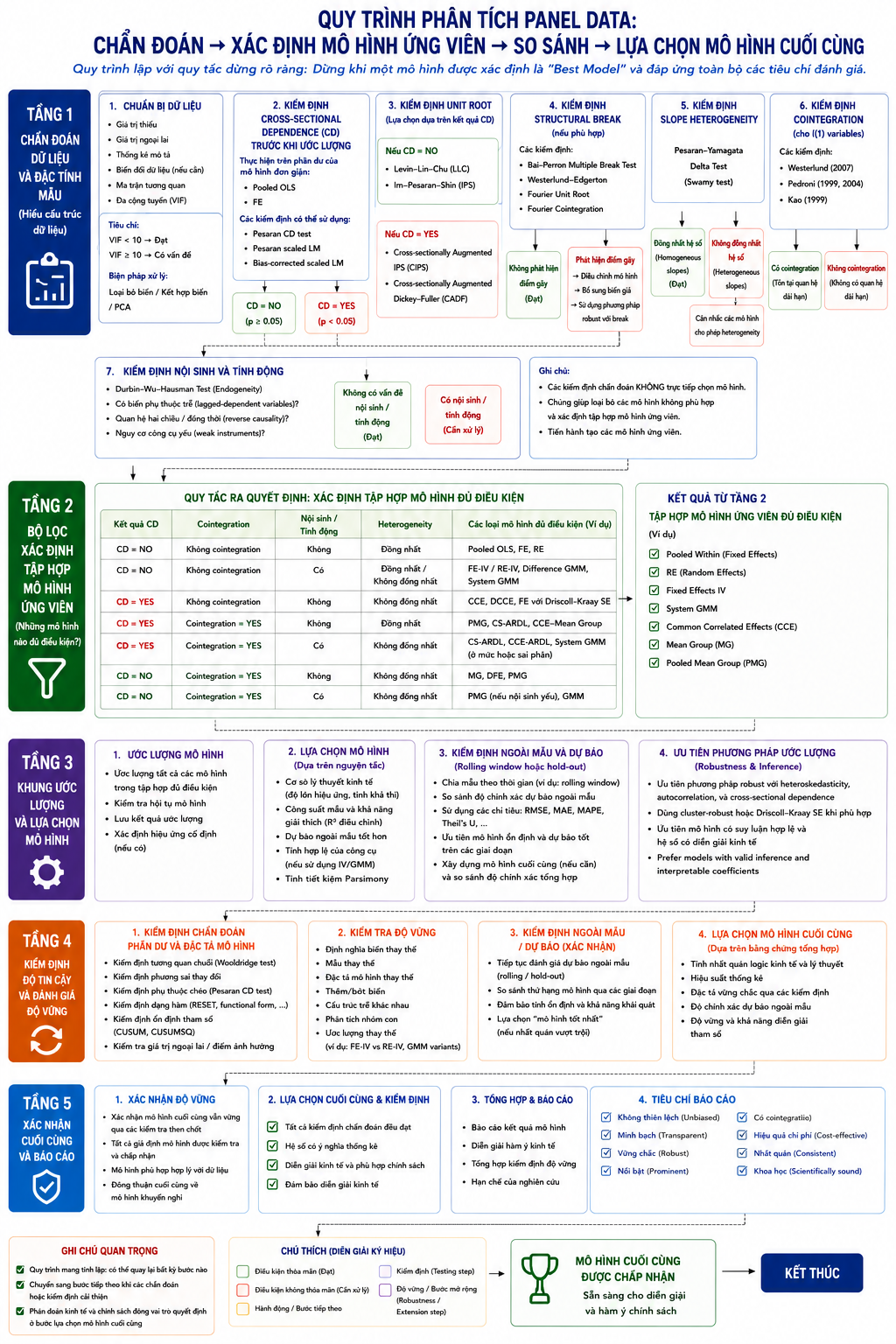
2. Mô hình dữ liệu bảng tĩnh là khởi điểm phân tích
Khung phân tích cổ điển bắt đầu với ba bộ ước lượng: pooled OLS, FE và RE. Các mô hình này được gọi là “tĩnh” vì giả định rằng biến phụ thuộc hiện tại chỉ phụ thuộc vào các biến giải thích cùng thời kỳ, không xét đến độ trễ của chính nó.
Pooled OLS là mô hình có ràng buộc mạnh nhất khi giả định đồng nhất hoàn toàn giữa các đơn vị chéo, bao gồm cả hệ số chặn và hệ số góc. Giả định này thường không phù hợp trong nghiên cứu về quốc gia, doanh nghiệp hay hộ gia đình, nơi dị biệt không quan sát được luôn tồn tại.
Mô hình FE nới lỏng giả định trên bằng cách cho phép mỗi đơn vị có một hệ số chặn riêng và không đổi theo thời gian. Thông qua biến đổi “within”, FE loại bỏ các yếu tố không quan sát được nhưng cố định theo thời gian, do đó phù hợp khi các đặc điểm không quan sát có tương quan với biến giải thích.
Mô hình RE tiếp cận theo hướng khác, xem hiệu ứng riêng của từng đơn vị là biến ngẫu nhiên và giả định không tương quan với biến giải thích. Trong điều kiện giả định này đúng, RE hiệu quả hơn FE do khai thác được cả biến thiên trong và giữa các đơn vị. Tuy nhiên, khi giả định trực giao bị vi phạm, RE trở nên không nhất quán, và kiểm định Hausman trở thành công cụ quyết định lựa chọn giữa FE và RE.
Dù FE và RE vẫn là nền tảng quan trọng, các mô hình này được xây dựng dưới những giả định ngày càng khó duy trì trong dữ liệu kinh tế hiện đại, đặc biệt là giả định độc lập chéo, đồng nhất hệ số và ngoại sinh tuyệt đối.
3. Phụ thuộc chéo và các phương pháp thế hệ hai
Một bước tiến quan trọng trong kinh tế lượng dữ liệu bảng là thừa nhận rằng các đơn vị kinh tế không độc lập. Các quốc gia cùng chịu ảnh hưởng từ khủng hoảng tài chính toàn cầu, các khu vực phản ứng với chính sách quốc gia, và doanh nghiệp cùng chịu tác động từ tiến bộ công nghệ.
Những yếu tố chung này tạo ra hiện tượng phụ thuộc chéo (cross-sectional dependence), khiến sai số giữa các đơn vị có tương quan với nhau.
Khi phụ thuộc chéo tồn tại, các ước lượng FE và RE vẫn có thể được tính toán, nhưng sai số chuẩn trở nên không đáng tin cậy và các tính chất tiệm cận bị phá vỡ, dẫn đến suy luận thống kê sai lệch.
Kiểm định Pesaran CD hiện được sử dụng rộng rãi để phát hiện phụ thuộc chéo. Khi hiện tượng này được xác nhận, hướng tiếp cận chuyển sang nhóm mô hình Common Correlated Effects (CCE). Ý tưởng cốt lõi của CCE là xấp xỉ các nhân tố chung không quan sát được thông qua trung bình chéo của biến phụ thuộc và biến giải thích.
Trong nhóm này, CCEMG cho phép đồng thời tồn tại nhân tố chung và dị biệt hệ số giữa các đơn vị, trong khi DCCE mở rộng sang khung động. Các mô hình này đặc biệt phù hợp trong nghiên cứu vĩ mô và phát triển, nơi các nền kinh tế vận hành trong một hệ thống liên kết chặt chẽ.
4. Tính dừng, nghiệm đơn vị và vấn đề hồi quy giả
Tiếp theo liên quan đến đặc tính chuỗi thời gian của biến. Các biến kinh tế như GDP, đầu tư trực tiếp nước ngoài, tiêu thụ năng lượng hay độ mở thương mại thường có xu hướng dài hạn và không dừng.
Hồi quy giữa các biến có xu hướng như vậy có thể tạo ra kết quả có ý nghĩa thống kê giả tạo, dù không tồn tại quan hệ kinh tế thực sự. Hiện tượng này được gọi là hồi quy giả (spurious regression).
Điều này dẫn đến sự phát triển của các kiểm định nghiệm đơn vị trong dữ liệu bảng, nhằm xác định liệu biến có dao động quanh giá trị trung bình dài hạn hay chứa xu hướng ngẫu nhiên.
Các kiểm định thế hệ thứ nhất như Levin–Lin–Chu (LLC) và Im–Pesaran–Shin (IPS) giả định độc lập chéo. Trong khi đó, các kiểm định thế hệ thứ hai như CADF và CIPS cho phép tồn tại nhân tố chung và phụ thuộc chéo.
Kết quả kiểm định nghiệm đơn vị đóng vai trò nền tảng cho lựa chọn mô hình tiếp theo: nếu biến dừng, có thể sử dụng trực tiếp các mô hình truyền thống; nếu biến tích phân bậc một, cần tiến hành phân tích đồng liên kết.
5. Đồng liên kết và mô hình hóa cân bằng dài hạn
Phân tích đồng liên kết xuất phát từ quan sát rằng nhiều biến kinh tế không dừng nhưng có xu hướng dịch chuyển cùng nhau trong dài hạn. Lý thuyết kinh tế thường dự đoán các mối quan hệ như vậy giữa tăng trưởng và độ mở thương mại, hoặc giữa phát triển tài chính và tăng trưởng kinh tế.
Kiểm định đồng liên kết trong dữ liệu bảng nhằm xác định sự tồn tại của quan hệ cân bằng dài hạn giữa các biến không dừng. Nếu không tồn tại đồng liên kết, các ước lượng dài hạn trở nên vô nghĩa vì các biến trôi dạt độc lập theo thời gian; khi đó, mô hình ngắn hạn (thường dưới dạng sai phân bậc nhất) trở nên phù hợp hơn.
Khi đồng liên kết được xác nhận, có thể sử dụng các bộ ước lượng chuyên biệt như Dynamic Fixed Effects (DFE), Mean Group (MG), Pooled Mean Group (PMG), Fully Modified OLS (FMOLS), Dynamic OLS (DOLS), và gần đây là CS-ARDL và DCCE.
Khác biệt cốt lõi giữa các mô hình này nằm ở giả định đồng nhất hệ số dài hạn. DFE áp đặt đồng nhất hoàn toàn; PMG cho phép dị biệt ngắn hạn nhưng ràng buộc dài hạn đồng nhất; MG cho phép hoàn toàn dị biệt và sau đó lấy trung bình kết quả.
6. Dị biệt tham số và cách tiếp cận Mean Group
Giả định các đơn vị phản ứng giống nhau trước thay đổi của biến giải thích thường không phản ánh thực tế trong nghiên cứu liên quốc gia. Tác động của đổi mới đến tăng trưởng có thể khác nhau giữa các quốc gia tùy thuộc vào thể chế, trình độ phát triển hoặc chất lượng nguồn nhân lực.
Từ nhận thức này, phương pháp Mean Group (MG) được phát triển. MG ước lượng riêng từng đơn vị rồi lấy trung bình các hệ số, cho phép dị biệt hoàn toàn trong cả ngắn hạn và dài hạn.
Mô hình PMG nằm giữa DFE và MG: giả định quan hệ dài hạn đồng nhất nhưng cho phép điều chỉnh ngắn hạn khác nhau. Trong nhiều nghiên cứu thực nghiệm, PMG được xem như sự cân bằng giữa hiệu quả ước lượng và tính linh hoạt mô hình.
Trong bối cảnh đồng thời tồn tại phụ thuộc chéo và dị biệt tham số, CCEMG và DCCE trở thành lựa chọn phù hợp hơn do xử lý đồng thời cả hai vấn đề.
7. Nội sinh và mô hình dữ liệu bảng động
Nội sinh là vấn đề phổ biến trong kinh tế thực nghiệm, xuất phát từ biến bị bỏ sót, quan hệ hai chiều, nhân quả ngược hoặc sai số đo lường. Ví dụ, đổi mới có thể thúc đẩy tăng trưởng, trong khi tăng trưởng cũng quay lại thúc đẩy đổi mới.
Các mô hình dữ liệu bảng động giải quyết vấn đề này bằng cách đưa biến phụ thuộc trễ vào mô hình và sử dụng công cụ nội sinh. Các đóng góp của Arellano–Bond, Arellano–Bover và Blundell–Bond hình thành nên hai bộ ước lượng quan trọng: Difference GMM và System GMM.
Difference GMM loại bỏ hiệu ứng cố định thông qua sai phân và sử dụng giá trị trễ làm công cụ. Tuy nhiên, khi chuỗi có tính bền vững cao, công cụ trở nên yếu. System GMM khắc phục bằng cách kết hợp phương trình ở mức và sai phân, cải thiện hiệu quả ước lượng.
Với các mẫu có N lớn và T nhỏ, System GMM thường là chuẩn tham chiếu khi có nội sinh. Tuy nhiên, phương pháp này không trực tiếp xử lý phụ thuộc chéo hoặc quan hệ đồng liên kết, do đó trong nhiều trường hợp, các mô hình CCE hoặc CS-ARDL có thể phù hợp hơn.
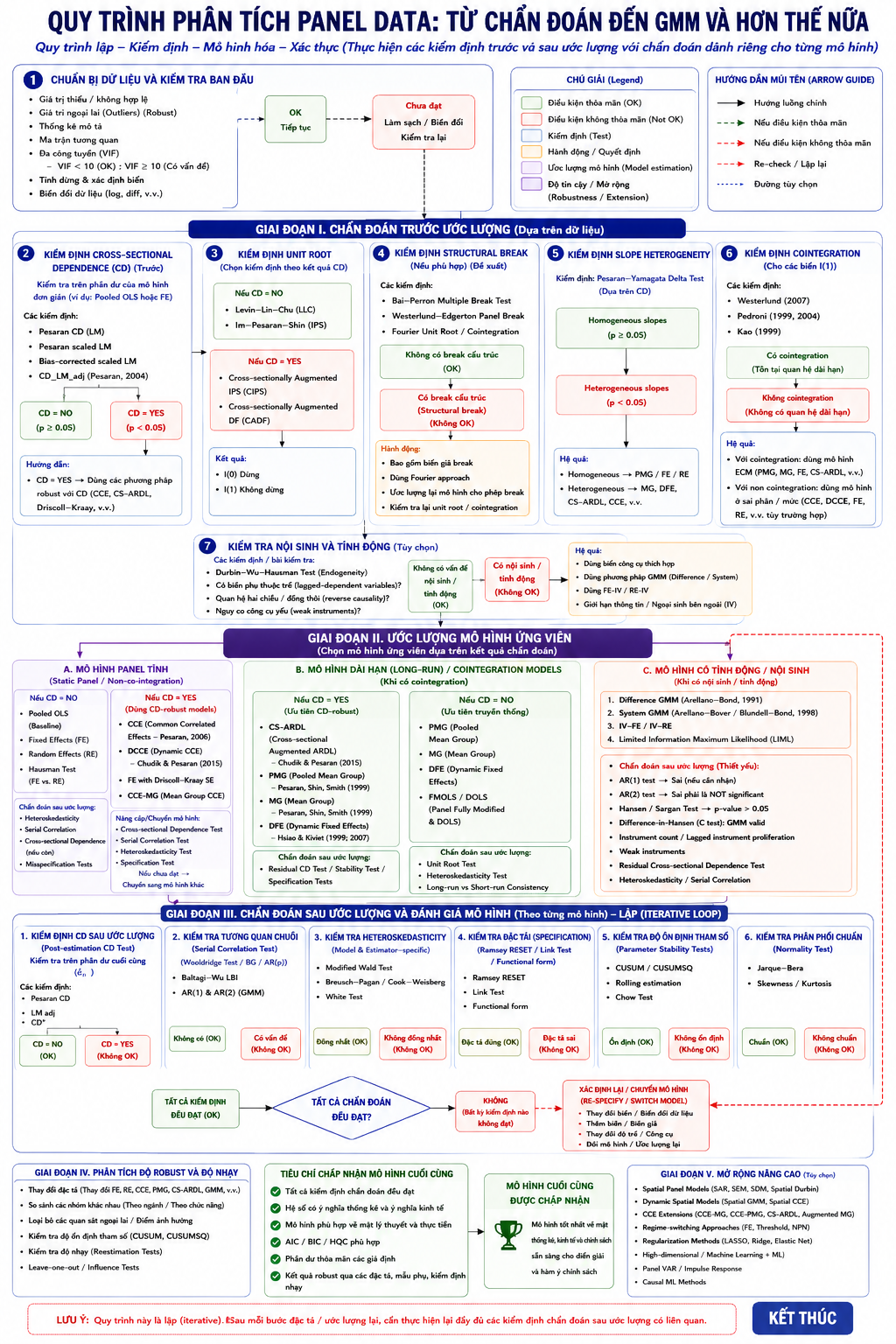
8. CS-ARDL trỗi dậy
Các nghiên cứu gần đây cho thấy hạn chế của các mô hình đồng liên kết truyền thống khi tồn tại phụ thuộc chéo. PMG, MG và DFE ban đầu được xây dựng dưới giả định độc lập chéo, vốn khó thỏa mãn trong các nền kinh tế liên kết mạnh.
CS-ARDL mở rộng khung ARDL bằng cách đưa vào trung bình chéo của biến nhằm xấp xỉ nhân tố chung không quan sát được. Nhờ đó, mô hình đồng thời xử lý tính không dừng, đồng liên kết, động học điều chỉnh, phụ thuộc chéo và dị biệt hệ số.
Chính sự tích hợp này khiến CS-ARDL ngày càng được sử dụng rộng rãi trong nghiên cứu kinh tế vĩ mô hiện đại. Trong nhiều trường hợp với T trung bình hoặc lớn, CS-ARDL có thể được xem như mở rộng tự nhiên của PMG trong môi trường có phụ thuộc chéo.
Do đó, nhiều nghiên cứu hiện nay thường sử dụng System GMM như mô hình cơ sở cho vấn đề nội sinh, đồng thời dùng CS-ARDL hoặc DCCE như kiểm định độ bền nhằm xử lý động học dài hạn và nhân tố chung.
9. Kích thước mẫu và lựa chọn mô hình
Hiệu quả tương đối của các mô hình phụ thuộc mạnh vào kích thước dữ liệu. Phân biệt giữa mẫu N lớn – T nhỏ và N nhỏ – T lớn là yếu tố then chốt trong thực hành.
Mẫu N lớn – T nhỏ phù hợp với FE, RE, Difference GMM và System GMM, do các mô hình này được xây dựng dựa trên tiệm cận khi số đơn vị tăng lên trong khi chiều thời gian hạn chế.
Ngược lại, mẫu N nhỏ – T lớn phù hợp với các mô hình khai thác thông tin dài hạn như MG, PMG, DFE, CS-ARDL, DCCE, FMOLS và DOLS.
Khi cả N và T đều lớn, không gian lựa chọn mô hình mở rộng đáng kể, cho phép sử dụng các kỹ thuật tiên tiến có khả năng xử lý đồng thời nhiều vấn đề kinh tế lượng.
10. Kiểm định mô hình và tính lặp của phân tích kinh tế lượng
Giai đoạn cuối cùng của phân tích dữ liệu bảng là kiểm định mô hình. Quá trình mô hình hóa không nên được hiểu như một chuỗi tuyến tính kết thúc ở bước ước lượng, mà là một quy trình lặp, trong đó các kiểm định chẩn đoán liên tục đánh giá mức độ phù hợp của mô hình với dữ liệu.
Phụ thuộc chéo trong phần dư cho thấy còn tồn tại nhân tố chung chưa được mô hình hóa. Tự tương quan phản ánh sai lệch trong đặc tả động học. Phương sai thay đổi ảnh hưởng đến hiệu quả thống kê. Kiểm định dạng hàm phát hiện biến bị bỏ sót phi tuyến. Kiểm định ổn định đánh giá tính nhất quán của hệ số theo thời gian.
Một mô hình chỉ được chấp nhận khi vượt qua đầy đủ các kiểm định này. Khi một kiểm định thất bại, điều đó không đồng nghĩa mô hình bị loại bỏ hoàn toàn, mà cho thấy cần điều chỉnh và ước lượng lại.
Do đó, mô hình tối ưu không phải mô hình tạo ra nhiều hệ số có ý nghĩa thống kê nhất, mà là mô hình có tính nhất quán lý thuyết, hợp lệ về thống kê và bền vững qua nhiều đặc tả khác nhau.
Theo cách nhìn này, kinh tế lượng dữ liệu bảng hiện đại là quá trình từng bước nhận diện cấu trúc của cơ chế sinh dữ liệu. Kiểm định xác định vấn đề, mô hình được chọn để xử lý vấn đề, và kiểm định hậu ước lượng xác nhận mức độ thành công của lựa chọn. Mô hình cuối cùng hình thành từ sự hội tụ giữa lý thuyết kinh tế, bằng chứng thống kê và tính hợp lệ kinh tế lượng.