1. PHÂN TÍCH KHÁM PHÁ DỮ LIỆU
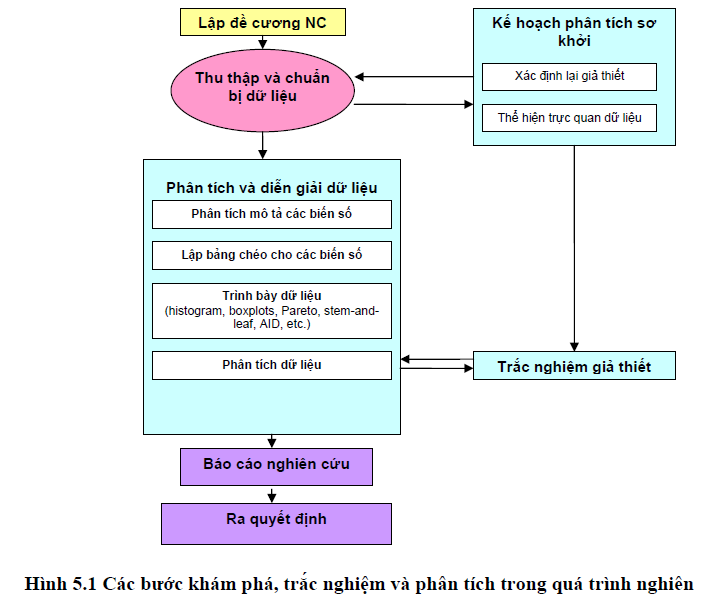
Khi dùng phân tích khám phá dữ liệu – exploratory data analysis (EDA) ta có khả năng linh động đáp ứng lại các khuôn mẫu khác nhau của bước phân tích dữ liệu sơ khởi. Cách thức phân tích này cho phép xem xét và đánh giá lại kế hoạch phân tích dữ liệu. Tính mềm dẻo là một thuộc tính quan trọng của cách tiếp cận này.
Phân tích xác nhận dữ liệu (Confirmatory data analysis) là một quá trình phân tích theo hướng suy luận từ kết quả phân tích thống kê dựa trên trắc nghiệm ý nghĩa và độ tin cậy.
2. NHẬP SỐ LIỆU
2.1. Cách bố trí dữ liệu trên máy tính
a. Mục tiêu:
- Nhằm tạo điều kiện thuận tiện cho việc nhập liệu
- Nhằm tạo sự thuận lợi cho việc chỉnh sửa dữ liệu
b. Thực hiện:
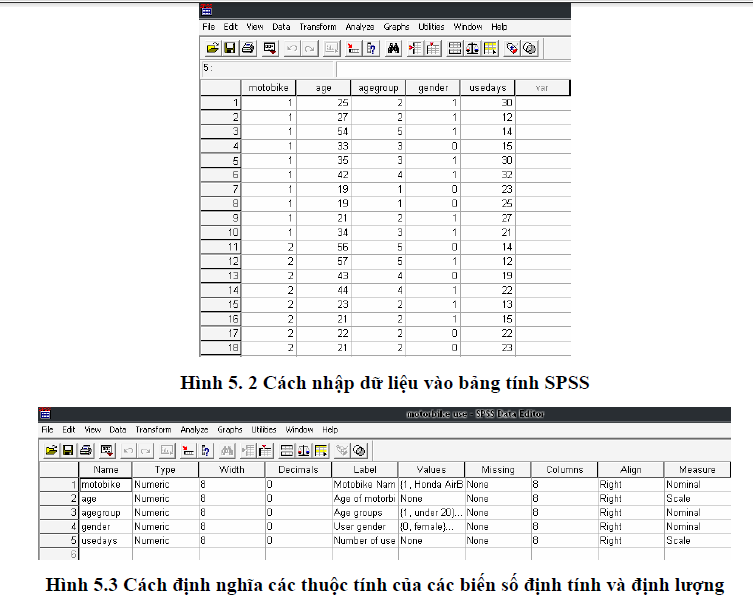
- Nguyên tắc chung: đặt tên biến ngắn gọn, nên viết tắt (nên sử dụng tiếng Việt không dấu hoặc sử dụng tiếng Anh). Tên biến nên được đặt theo quy luật và trình tự của bảng câu hỏi hay nội dung khảo sát.
- Nếu lưu trữ bằng phần mềm Excel: ưu điểm là dễ thao tác và chỉnh sửa, nhược điểm là không gian lưu trữ hạn chế, công cụ thống kê và kinh tế lượng phát triển chưa đầy đủ cho nhu cầu phân tích.
- Nếu lưu trữ bằng phần mềm SPSS: ưu điểm là không gian lưu trữ gần như không hạn chế, công cụ thống kê và kinh tế lượng phát triển khá đầy đủ cho nhu cầu phân tích. Nhưng nhược điểm là đòi hỏi việc khai báo dữ liệu mất nhiều thời gian hon.
2.2. Cách nhập liệu
a. Đối với dữ liệu định lượng: nhập đúng giá trị trong bảng phỏng vấn, nên thao tác bằng các phím tại ô số trên bàn phím.
b. Đối với dữ liệu định tính
- Câu trả lời đóng:
Trường hợp câu hỏi có 1 câu trả lời hoặc chọn 1 trong 2 (ví dụ: có hoặc không, nam hay nữ): sử dụng giá trị 0 và 1 để lưu thông tin. Ví dụ: có là 1 , không là 0, nam là 1 , nữ là 0 hoặc ngược lại.
Trường hợp có từ 3 lựa chọn trở lên nhưng chỉ có 1 câu trả lời (ví dụ: không thích, thích và không ý kiến): sử dụng giá trị 1, 2 và 3 tương ứng theo câu trả lời.
Trường hợp có từ 3 lựa chọn trở lên và có ít nhất 2 câu trả lời (ví dụ: câu hỏi về sở thích: xem tivi, đọc báo và nghe radio): Tạo 3 biến, mỗi biến là một lựa chọn và sử dụng giá trị 0 và 1 để lưu thông tin, lựa chọn nào được đánh dấu trong bảng câu hỏi thì biến tương ứng sẽ có giá trị 1, nếu không được chọn thì đánh số 0.
- Câu trả lời mở: nhập chính xác câu trả lời ghi trong bảng câu hỏi, sau đó đọc và phân nhóm câu trả lời rồi mã hóa.
Chú ý: Cần phải tạo 1 file để chứa tên và giải thích ý nghĩa của các biến có trong dữ liệu để thuận tiện cho việc phân tích và kế thừa dữ liệu.
3. THANH LỌC DỮ LIỆU (Data Screening)
3.1. Phát hiện giá trị dị biệt trong dữ liệu
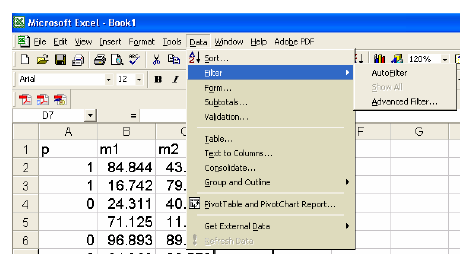
a. Sử dụng Excel: hàm Max và Min, công cụ Auto Filter, đồ thị Scatter.
b. Sử dụng SPSS: đồ thị Scatter, công cụ Frequency, Bar Chart, Pie Chart, và Box Plot trong Explore
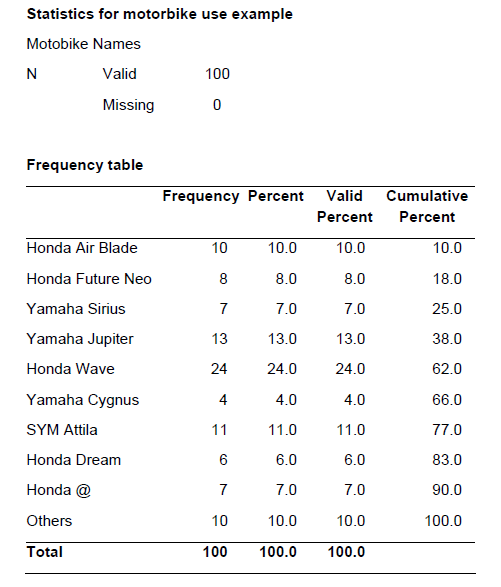
i. Bảng tần suất (Frequency Tables)
Bảng tần suất là một công cụ đơn giản để sắp xếp dữ liệu. Nó giúp sắp xếp dữ liệu theo giá trị số, với các cột thể hiện các chỉ số phần trăm, phần trăm có hiệu lực (phần trăm sau khi điều chỉnh số liệu mất), và phần trăm cộng dồn.
Ví dụ 5.1 Bảng tần suất của biến số Nhãn hiệu xe máy được sử dụng Statistics for motorbike use example Motobike Names
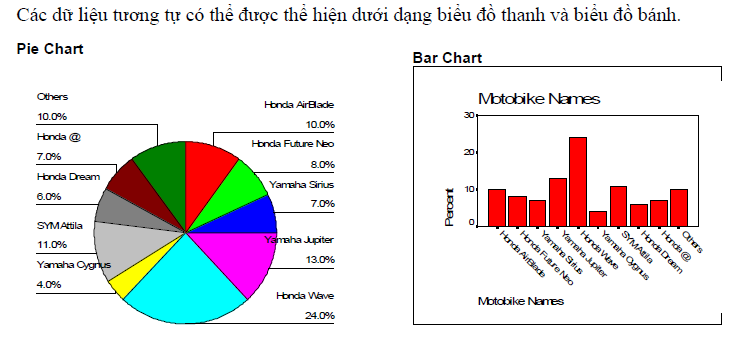
ii.Biểu đồ thanh (Bar Charts) và Biểu đồ bánh (Pie Charts)
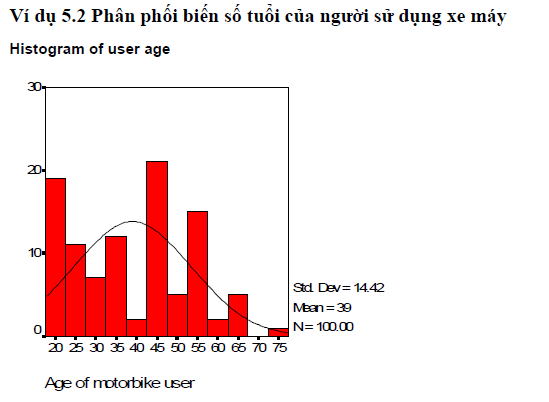
iii. Biểu đồ Histograms
Biểu đồ histogram là một giải pháp quy ước dùng để thể hiện các dữ liệu tỷ lệ hoặc khoảng cách. Biểu đồ histogram được sử dụng để phân nhóm các giá trị dữ liệu của các biến số (variable) thành các khoảng cách. Biểu đồ histogram được xây dựng dưới dạng các thanh thể hiện giá trị dữ liệu.
Biểu đồ histogram rất hữu dụng cho việc: (1) thể hiện tất cả các khoảng cách trong một phân phối (distribution), và (2) trắc nghiệm dạng hình của phân phối như độ méo (skewness), độ nhọn (kurtosis).
Ghi chú: Biểu đồ histogram không dùng được cho các biến danh nghĩa.
iv. Biểu đồ Thân-và-Lá (Stem-and-Leaf Displays)
Mỗi dòng của biểu đồ được gọi là một thân; và mỗi số liệu thể hiện trên một thân gọi là một lá.
Theo ví dụ 7.3, ý nghĩa của dòng (thân) thứ nhất là có 6 số liệu có chữ số đầu là 1 (hàng chục) là 18, 18, 19, 19, 19, 19.

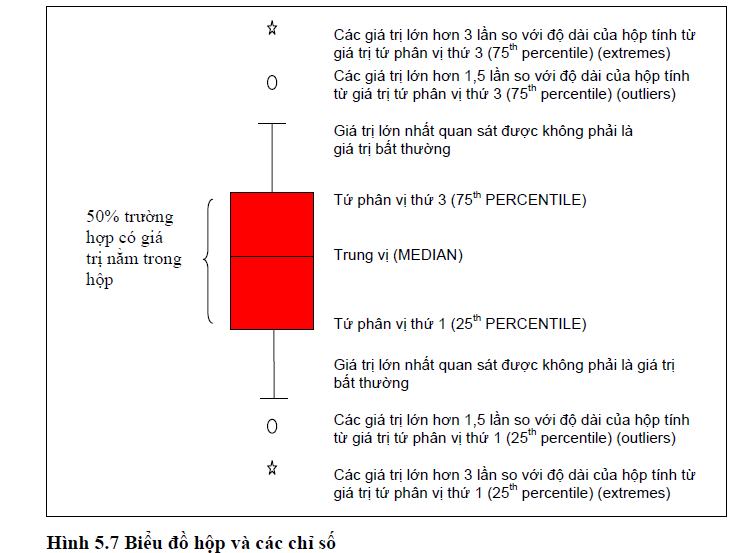
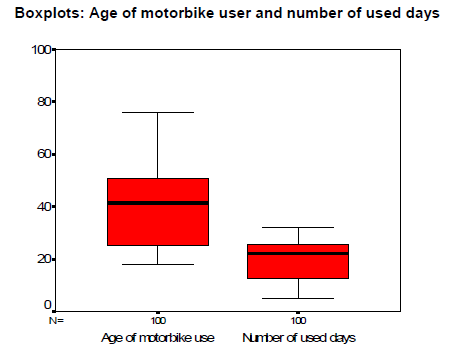
v. Biểu đồ hộp (Box Plots)
Biểu đồ hộp, hay còn gọi là biểu đồ hộp-và-râu (box-and-whisker plot), cho ta một hình ảnh trực quan khác về vị trí, độ phân tán, dạng hình, độ dài đuôi và các giá trị bất thường (outliers) của phân phối.
Biểu đồ hộp thể hiện tóm tắt 5 giá trị thống kê của một phân phối là trung vị (median), hai tứ phân vị trên và dưới (the upper and lower quartiles), và các giá trị quan sát lớn nhất và nhỏ nhất. Các thành phần chủ yếu của biểu đồ hộp là:
- Hộp hình chữ nhật chứa đựng 50% các giá trị dữ liệu.
- Đường thẳng ở trung tâm hộp là giá trị trung vị.
- Hai lề của hộp thể hiện hai giá trị tứ phân vị thứ 1 và thứ 3 (tương ứng với giá trị thứ 25% (25th percentile) và giá trị thứ 75% (75th percentile) của dãy số liệu.
- Các “râu” kéo dài từ lề phía trên và phía dưới của hộp thể hiện giá trị lớn nhất và nhỏ nhất. Các giá trị này nằm trong khoảng tối đa 1,5 lần khoảng cách giữa các tứ phân vị tính từ lề của hộp.
Khi trắc nghiệm dữ liệu, điều quan trọng là phải tách biệt các giá trị bất thường sinh ra từ các lỗi đo lường, hiệu đính, mã hóa và nhập dữ liệu. Các giá trị bất thường này vượt quá 1,5 lần khoảng cách tứ phân vị.
3.2. Phát hiện và xử lý dữ liệu bị khuyết (Missing data)
- Sử dụng Excel: công cụ Auto Filter.
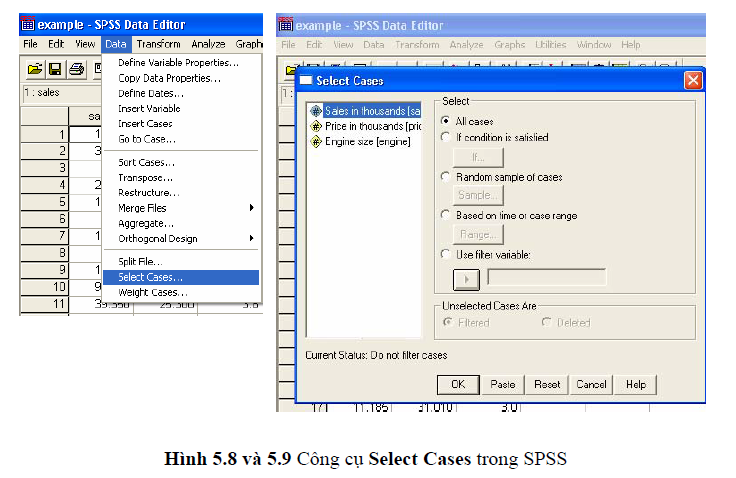
- Sử dụng SPSS: công cụ Frequency và Select Cases.