Phần thứ 2: Giới thiệu về các khái niệm biến quan sát, tiềm ẩn, bậc tự do, sai số, phần dư, ẩn tàng, tường minh, tính xác định của mô hình…
- Các phần tử trong mô hình mạng (SEM)
Biến quan sát (Observed variable): còn gọi là biến chỉ báo (cấu tạo/phản ánh), biến đo lường, biến ngoại sinh hay biến độc lập…tùy trường hợp cụ thể.Trong hình 1a, mô hình biến quan sát được biểu diễn bằng hình chữ nhật (V1, V2, V3). Biến V1, V2, V3 có mũi tên đi ra nên trong trường hợp này còn được gọi là biến ngoại sinh hay biến độc lập (trong mô hình truyền thống). Trong hình 1b, mô hình biến quan sát V1, V2, V3 phản ánh biến tiềm ẩn F và biến tiềm ẩn F đóng vai trò biến ngoại sinh (nguyên nhân) trong mô hình SEM. (sẽ nói kỹ hơn ở phần phân biệt biến chỉ báo cấu tạo và biến chỉ báo phản ánh phía dưới)
Hình 1: Mô hình biểu diễn quan hệ giữa các biến quan sát và biến tiềm ẩn

Sự liên kết của các biến quan sát (chỉ báo) với các biến tiềm ẩn (không quan sát) là bước đầu tiên trong một thủ tục thống kê hình thức. Trái lại thông thường các thủ tục liên kết thường “ẩn tàng”-nếu ta cảm thấy một biến đo được nào đó có chỉ báo tốt của một khái niệm tiềm ẩn nào đó, thì chúng ta sẽ dùng nó.
Biến tiềm ẩn(Latent Variable):còn gọi là nhân tố, biến nội sinh hay biến phụ thuộc trong mô hình truyền thống(hình 1a). Trái lại, trong mô hình SEM, biến tiềm ẩn trực tiếp ảnh hưởng kết quả hay giá trị của biến quan sát và biểu diễn dưới dạng hình ellipse(F1) như hình 2. Biến tiềm ẩn (nhân tố) F1 thể hiện một khái niệm lý thuyết, không thể đo trực tiếp được mà phải thông qua các biến quan sát V1, V2,V3. Trường hợp này biến F1 còn được gọi là nhân tố cơ sở (Underlying factor), trong mô hình đo lường.
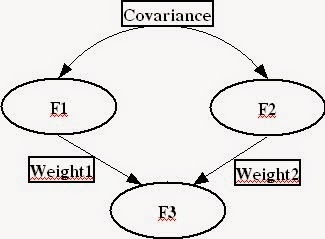
Các biến tiềm ẩn hay các nhân tố cơ sở (F1, F2, F3) hay các sai số đo lường (e1,e2,e3) có thể tương quan với nhau ( mũi tên 2 chiều) hay có thể ảnh hưởng trực tiếp biến tiềm ẩn khác (mũi tên 1 chiều). Biến F3 trên hình vẽ có các mũi tên đi vào nên còn được gọi là biến nội sinh hay biến phụ thuộc ( trong mô hình hồi quy hay mô hình cấu trúc).
Hình 3:Ví dụ một mô hình cấu trúc
Số hạng sai số và phần dư (Error & Disturbance):
Số hạng sai số ei biểu thị sai số của các biến đo lường, trong khi di biểu thị cho nhiễu hoặc sai số liên quan với giá trị dự báo của các nhân tố(biến) nội sinh từ các nhân tố(biến) ngoại sinh hay còn gọi là phần dư của ước lượng hồi quy.
Trong mô hình đo lường của SEM (hình 4), mỗi biến nội sinh có một số hạng sai số(ei) hay nhiễu(di), nó thể hiện tính không chắc chắn và không chính xác của sự đo lường, đồng thời nó còn thể hiện tính chất này cho cả các biến chưa được phát hiện và không được đo lường trong mô hình.
Hình 4: các phần tử cơ bản trong mô hình SEM

Lưu ý rằng biến nội sinh là biến phụ thuộc vào biến khác ( V1,V2…,V6 và F3) có mũi tên vào/ra, còn biến ngoại sinh là biến không phụ thuộc vào biến khác (F1, F2) chỉ có mũi tên đi ra (không có bất kỳ nhiễu d hay bất kỳ sai số e nào) Ngoài ra, cũng cần phân biệt mũi tên một chiều giữa các biến tiềm ẩn và các biến quan sát biểu thị các hệ số tải (factor loadings) trong khi mũi tên một chiều giữa các khái niệm tiềm ẩn và các biến quan sát lại biểu thị hệ số hồi quy (regression coefficients)
Tóm lại, Một mô hình SEM đặc trưng là một phức hợp giữa một số lượng lớn các biến quan sát và không quan sát, các số hạng phần dư và các sai số.
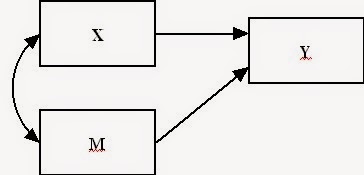
Biến trung gian ( Mediator): Gọi X là biến nguyên nhân gốc, M là biến trung gian tiềm năng(hình 5), và Y là biến kết quả. Để xác định M là biến trung gian:
- a) Chứng minh rằng X —- > Y : Y liên quan với X,
- b) Chứng minh rằng X —- > M : M liên quan với X,
- c) Chứng minh rằng M — > Y là liên kết có ý nghĩa trong hồi quy hai biến dự báo
Hình 5: Biến trung gian trong mô hình SEM
- d) Giả định các kiểm định trên đều thỏa mãn, khi đó:
- i) Nếu liên kết : X — >Y không có ý nghĩa ở c) : M trung gian toàn phần;
- ii) Nếu liên kết : X — >Y có ý nghĩa ở c) : M trung gian một phần.
Nếu một khái niệm ( construct) làm trung gian trong tác động của các biến ngọai sinh lên một biến phụ thuộc, phải đưa các quan hệ chức năng này vào mô hình. Các biến ngọai sinh nếu là biến trung gian một phần(tức là một liên kết trực tiếp hay gián tiếp với một biến phụ thuộc) thường là các biến dự báo quan trọng hơn cho một biến phụ thuộc, hơn là các biến tương tự: biến trung gian toàn phần. Nếu các tác động trung gian không được xem xét thích hợp ta có thể bị nhầm lẫn về sự quan trọng tương đối của các nhân tố khác nhau trong sự tác động lên một khái niệm.
Phân biệt khái niệm “Ẩn tàng” và khái niệm “Tường minh”

Biến chỉ báo phản ánh (Reflective Indicators) có quan hệ liên đới với nhau, sự thay đổi của một biến chỉ báo này kéo theo sự thay đổi của biến chỉ báo khác thể hiện qua tính nhất quán cục bộ được đo bằng hệ số Cronbach’s Alpha.
Biến chỉ báo cấu tạo (Formative Indicators) không cần thiết có liên quan với nhau, sự thay đổi của một biến chỉ báo này không ảnh hưởng đến các biến chỉ báo khác, do vậy không áp dụng đo tính nhất quán.
Hai khái niệm này được phối hợp lại trong mô hình nghiên cứu trong đó biến chỉ báo cấu tạo là nguyên nhân trong khi biến chỉ báo phản ánh thì phản ánh kết quả.

- Tính xác định của mô hình SEM
Tính xác định có nghĩa là có ít nhất một lời giải độc nhất cho mỗi ước lượng thông số trong một mô hình SEM. Số thông số cần ước lượng bằng số phương sai (Variance) hay hiệp phương sai(Covariance) của các biến ngoại sinh (biến quan sát hay không quan sát) và các tác động trực tiếp của các biến quan sát lên các biến nội sinh.
Để xác định mô hình nghiên cứu thuộc loại mô hình nào trong ba loại mô hình “Vừa xác định- Just Identification”; “Kém xác định- Under Identification” hay “Quá xác định- Over Identification” thì cần phải tính toán số bậc tự do của mô hình.
Bậc tự do là sự khác biệt giữa tổng số dữ liệu quan sát đầu vào (data points) và tổng số các thông số ước lượng trong SEM , được xác định bằng công thức sau:
df = 1/2[(p + q)(p + q +1)] – t
Trong đó:
p= số các biến chỉ báo nội sinh
q= số các biến chỉ báo ngoại sinh
(p+q = số biến quan sát)
t= Số các thông số ước lượng
½[(p+q)(p+q+1) = Số quan sát hay hiệp phương sai trong ma trận (data points)
1) Mô hình “vừa xác định” (Just Identification): Mô hình có df =0 và chỉ có một lời giải khả dĩ cho mỗi ước lượng thông số. Ví dụ: 2x+y =7; 3x+2y=11
2) Mô hình “kém xác định” (Under Identification): Mô hình có df < 0 và có vô số các giá trị ước lượng thông số. Vi dụ : 2x +y =7
3) Mô hình “quá xác định”(Over Identification): Mô hình có df > 0 và có hơn một lời giải khả dĩ (nhưng có một lời giải tối ưu hay tốt nhất đối với mỗi ước lượng thông số). Mô hình “quá xác định” xảy ra khi mỗi thông số được xác định và ít nhất một thông số thì “quá xác định” (có nhiều hơn một phương trình cho ước lượng thông số này). Thông thường mô hình “quá xác định” được ưa thích hơn, có bậc tự do dương (df>0). Mục tiêu là đạt được df càng lớn càng tốt.
Việc đặt các hạn chế(ràng buộc) trên mô hình “quá xác định” cho chúng ta kiểm định các giả thuyết (dùng Chi Square và các chỉ số khác).
Sự “xác định” là một yêu cầu về cấu trúc hay toán học để có thể tiến hành phân tích SEM.
Sự “kém xác định” trong thực nghiệm xuất hiện khi có một thông số ước lượng tính “xác định” của mô hình có giá trị gần bằng 0. Do tính chất lặp của ước lượng SEM, một thông số ước lượng (phương sai chẳng hạn) bắt đầu với giá trị dương và tiến dần về giá trị 0.
Trong nghiên cứu mô hình SEM cần cố gắng xác định nguyên nhân của tính kém xác định là do cấu trúc hay kém xác định do thực nghiệm.
– Nếu kém xác định do cấu trúc: Xác định lại mô hình
– Nếu kém xác định do thực nghiệm: điều chỉnh bằng cách thu thập thêm dữ liệu hay xác định lại mô hình.
Ngoài ra nhóm hotrospss@gmail.com có các dịch vụ sau:
– Tư vấn mô hình/bảng câu hỏi/ traning trực tiếp về phân tích hồi quy, nhân tố, cronbach alpha… trong SPSS, và mô hình SEM, CFA, AMOS
– Thu thập/Xử lý số liệu khảo sát để chạy ra kết quả có ý nghĩa thống kê.