Sau khi thực hiện xong phân tích nhân tố khám phá. Để tiến hành phân tích tương quan Peason và hồi quy, chúng ta cần tạo các biến đại diện từ kết quả xoay nhân tố.

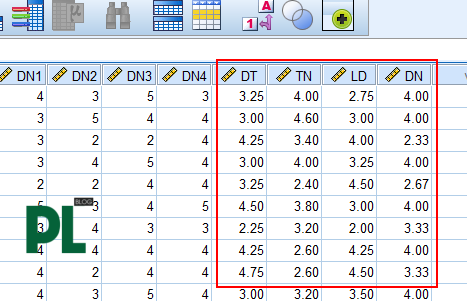
Bước thực hiện phân tích nhân tố khám phá, khi kết quả phân tích lần cuối cùng chấm dứt. Các biến quan sát được sắp xếp theo từng cột như hình minh họa bên dưới.
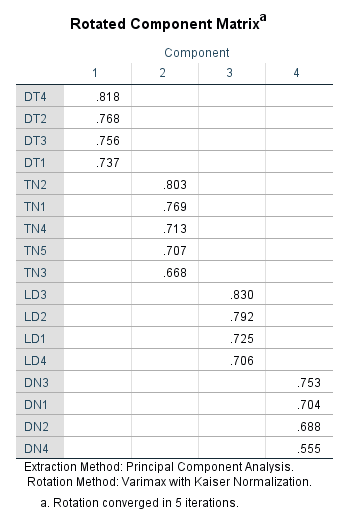
Từ kết quả ở trên, ma trận nhân tố cho chúng ta 5 nhân tố. Mỗi nhân tố sẽ gồm các biến quan sát nằm chung trên 1 cột. Chúng ta không thể thực hiện hồi quy trực tiếp với số lượng lớn biến quan sát mà cần thu gọn tập hợp biến này lại bằng các biến đại diện. Biến đại diện là biến thể hiện được tính chất chung của các biến quan sát trong cùng 1 cột. Có 2 cách tạo biến đại diện:
Cách 1: Biến đại diện bằng trung bình cộng của các biến trong một cột
Đây là cách phổ biến nhất và là tối ưu nhất. Cùng thực hiện với ví dụ ở hình ảnh bên trên. Tạo biến đại diện DT cho nhóm DT1, DT2, DT3, DT4:
Tại giao diện SPSS, vào Transform > Compute Variable:
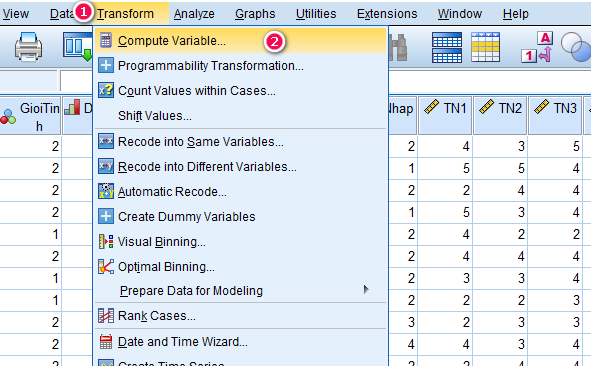
Giao diện cửa sổ mới hiện ra như hình dưới.
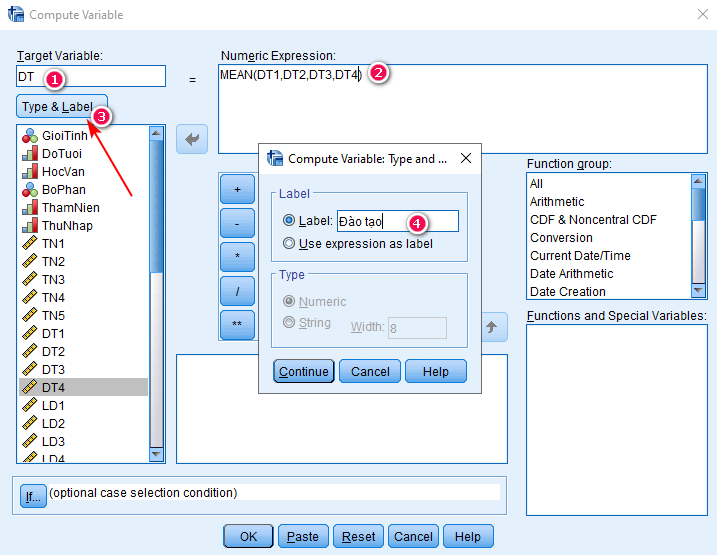
- Target Variable: Nhập tên biến đại diện mới là DT.
- Numeric Expression: Gõ hàm trung bình MEAN(DT1,DT2,DT3,DT4). Nghĩa là tạo biến đại diện DT là trung bình cộng của các biến quan sát DT1, DT2, DT3, DT4. Lưu ý, trong hàm MEAN, giữa các biến là dấu phẩy và không có khoảng cách trắng. Thứ tự biến không cần phải theo thứ tự trong ma trận xoay, các bạn có thể sắp xếp tùy ý, miễn là đủ biến trong một nhóm.
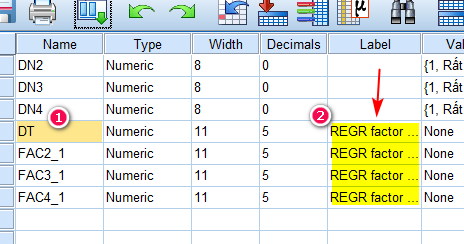
- Type & Label: Nhập chú thích cho biến, vai trò của nó giống như Label khi các bạn tạo biến trong cửa sổ giao diện Variable View. Ví dụ biến DT là đại diện cho nhóm biến quan sát: DT1, DT2, DT3, DT4, bạn chú thích nhóm này là Đào tạo thì sẽ gõ vào mục Type & Label. Phần này các bạn có thể nhập hoặc không, mục này không bắt buộc.
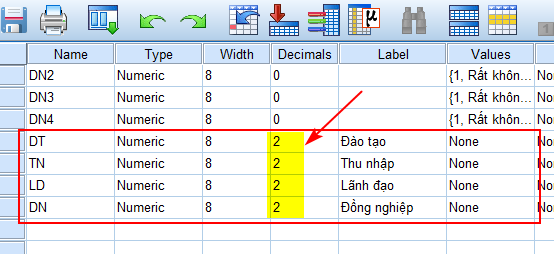
Sau khi đã nhập hàm, các bạn nhấp vào OK. Thực hiện tương tự cho các nhóm còn lại. Sau đó, quay lại giao diện Data View hoặc Variable View chúng ta sẽ thấy được các biến đại diện vừa mới được tạo ra bên cạnh các biến quan sát ban đầu. Các bạn nên chỉnh Decimals của các biến đại diện này thành 2, bởi hàm trung bình cộng MEAN sẽ tạo ra biến là số lẻ chứ không tròn trĩnh.
Cách 2: Biến đại diện bằng Factor Scores
SPSS có hỗ trợ tạo biến đại diện bằng Factor Scores tự động ở giao diện tùy chọn của EFA. Tuy nhiên, cách này mình không khuyến khích sử dụng bởi nó sẽ loại bỏ đi toàn bộ các sai số, loại bỏ đi một số vi phạm giả định hồi quy OLS. Chính vì vậy mà kết quả sẽ không được chính xác, dẫn đến việc chúng ta đưa ra những nhận định sai lầm nếu mô hình hồi quy vi phạm các giả định.
Để thực hiện tạo biến đại diện theo cách này. Tại cửa sổ Factor Analysis, chúng ta vào Scores, tích vào Save as variables, chọn vào Regression.
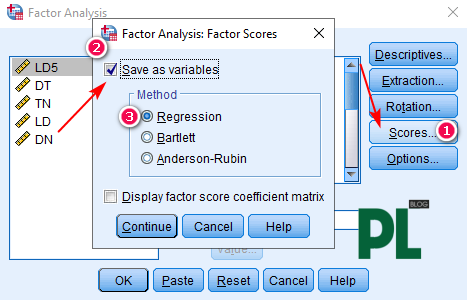
Nhấn Continue > OK, quay lại giao diện Data View hoặc Variable View chúng ta sẽ thấy các biến đại diện được tạo ra: FAC1_1, FAC2_1, FAC3_1, FAC4_1.
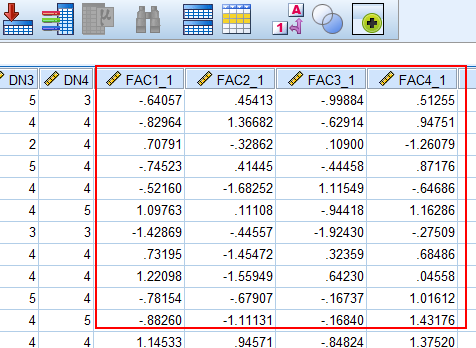
FAC1_1 là biến đại diện của cột đầu tiên trong ma trận xoay EFA, chính là nhóm DT1, DT2, DT3, DT4. Tương tự FAC2_1 là biến đại diện của nhóm TN1, TN2, TN3, TN4, TN5…
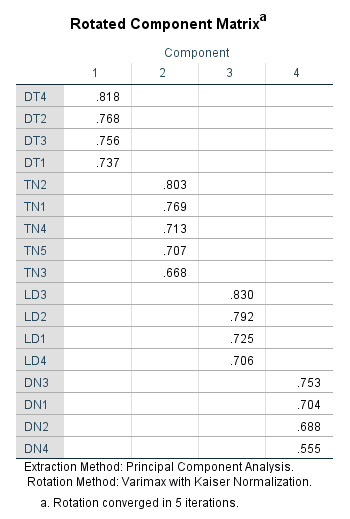
Các bạn nên trở lại giao diện Variable View, đổi tên các biến này sang ký hiệu để dễ đọc kết quả hơn. Ví dụ: đổi FAC1_1 thành DT, đổi FAC2_1 thành TN… và xóa bỏ các Label đi hoặc đổi tên Label cho dễ nhận diện biến.
Trên đây là 2 cách tạo biến đại diện trong SPSS để phục vụ các phân tích sau EFA. Như đã trình bày chi tiết, các bạn nên ưu tiên chọn cách số 1 nếu đề tài của bạn sử dụng thang đo Likert bởi nó phản ánh kết quả thực tế tốt hơn cách số 2.