Phân tích biệt số là gì?
Phân tích phân biệt được dùng để giải quyết một số tình huống khi nhà nghiên cứu muốn tìm thấy sự khác biệt giữa những nhóm đối tượng nghiên cứu với nhau, ví dụ phân biệt khách hàng trung thành và không trung thành bằng một số đặc điểm nhân khẩu học, phân biệt các phân khúc khách hàng bằng một số tiêu chí lợi ích khi sử dụng một sản phẩm…
Điều kiện của phân tích phân biệt là phải có một biến phụ thuộc (là biến dùng để phân loại đối tượng thường sử dụng thang đo định danh hoặc thứ tự), và một số biến độc lập (là một số đặc tính dùng để phân tích sự khác biệt giữa các nhóm đối tượng, thường sử dụng thang đo khoảng hoặc tỷ lệ). Phân tích biệt số có thể thực hiện các việc sau:
-Xây dựng các hàm phân tích phân biệt (discriminant functions) để phân biệt rõ xã biểu hiện của biến phụ thuộc.
-Nghiên cứu xem các nhóm có sự khác biệt có ý nghĩa hay không khi được xét về các yếu tố độc lập.
-Xác định biến độc lập là nguyên nhân chính nhất gây ra sự khác biệt giữa các nhóm.
Có 2 trường hợp phân tích biệt số: phân tích biệt số 2 nhóm (khi biến phụ thuộc có 2 biểu hiện), phân tích biệt số bội (khi biến phụ thuộc có từ 3 biểu hiện trở lên).
Ví dụ phân tích biệt số
Khi phân tích về lợi nhuận của những hộ tham gia làng nghề nhà nghiên cứu đã phân thành 2 nhóm: hộ có lợi nhuận (lợi nhuận > 0) và hộ không có lợi nhuận (LN ≤ 0). Nhà nghiên cứu muốn xem xét sự khác biệt giữa 2 nhóm hộ có lợi nhuận như trên về các yếu tố: tuổi, năm kinh nghiệm, vốn, số lao động, số mặt hàng, tính chất làng nghề (1-đã được công nhận, 0 – chưa được công nhận), tính chất hoạt động của hộ (1-hộ chuyên, 0 – hộ kiêm).
Thực hành phân tích biệt số trên SPSS
Bước 1. Chia mẫu quan sát thành 2 phần
Đối với phân tích phân biệt, ta phải chia mẫu quan sát thành 2 phần: mẫu ước lượng hay mẫu phân tích (là phần dung để ước lượng hàm phân biệt); phần còn lại là để kiểm tra tính đúng đắn của hàm phân biệt (mẫu kiểm tra). Khi cỡ mẫu đủ lớn, ta có thể chia thành 2 phần bằng nhau và theo tỷ lệ của toàn bộ mẫu.
Ví dụ: trong ví dụ trên, cỡ mẫu là 122 mẫu (có 66 mẫu ko có LN – chiếm 54% và 56 mẫu có LN – chiếm 46%). Ta sẽ tiến hành chia thành 2 phần, mỗi phần gồm 61 mẫu: trong đó có 33 mẫu ko có LN và 28 mẫu có LN.
Bước 2. Tiến hành phân tích biệt số trên SPSS
Vào Analyze ->Classify->Discriminant, xuất hiện hộp thoại sau:
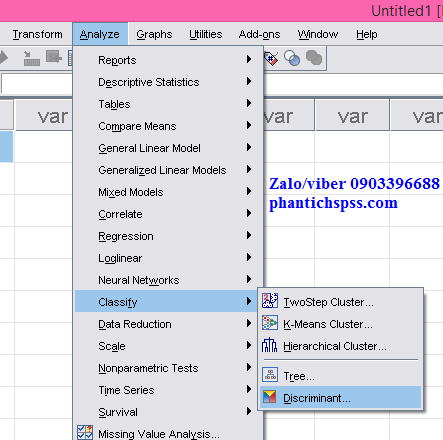
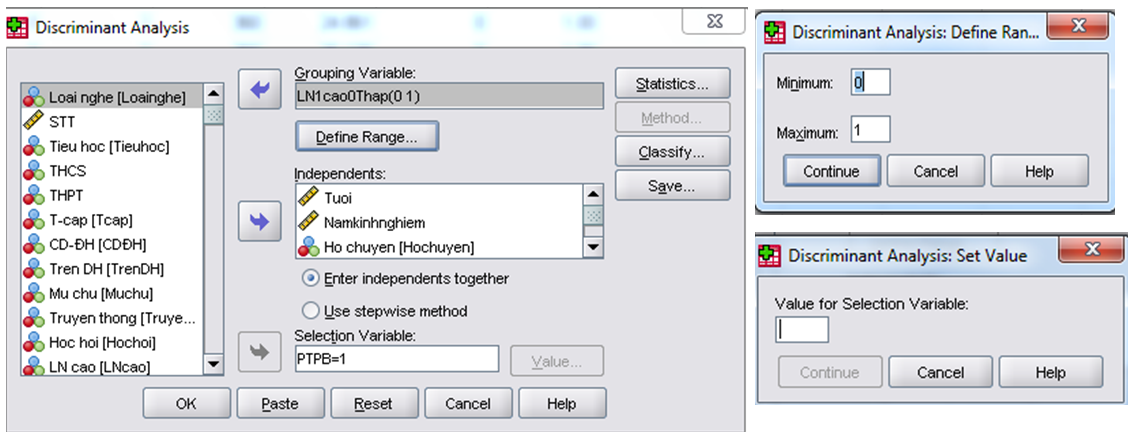
– Đưa biến phân loại 2 nhóm hộ có LN khác nhau vào ô Grouping Variable -> Khai báo Define Range (1 là hộ có TN, 0 là hộ ko có TN) -> Continue.
– Đưa các biến độc lập vào ô Independents.
– Xác định biến quan sát dùng để phân tích và kiểm tra tại ô Selection Variable. Tiếp theo sẽ khai báo Value. Khi phân chia mẫu ở bước 1, ta đã mã hóa nhóm dùng để phân tích là 1, nhóm dùng để kiểm tra là 0, nên sẽ nhập số 1 vào ô Value for Selection Variable. -> Continue.
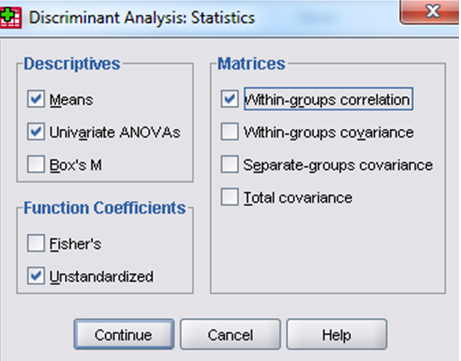
-Tiếp theo chọn nút Statistics và khai báo như sau: trung bình, bảng phân tích phương sai đơn, các ma trận hệ số tương quan và hiệp phương sai…
– Tiếp theo chọn nút Classify, và khai báo các phần như sau -> Continue
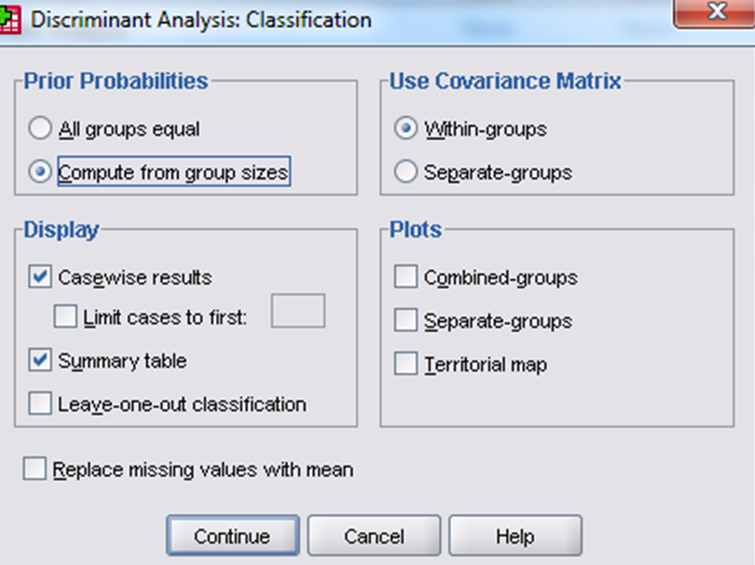
·Tại ô Prior Probabilities: xác suất dung để phân biệt đối tượng. Có 2 cách xác định: Xác suất bằng nhau giữa các nhóm (All groups equal), Xác suất theo tỷ lệ hay quy mô của các nhóm (Compute from group sizes).
· Display: thể hiện kết quả chi tiết của từng quan sát (case wise results), bảng kết quả phân biệt tóm tắt (summary table).
· Use Vovariance Matrix: phân biệt các quan sát bằng ma trận hiệp phương sai nội bộ các nhóm trung bình hay bằng ma trận hiệp phương sai các nhóm riêng biệt.
· Plots: vẽ biểu đồ phân tác chung cho các nhóm hay riêng cho từng nhóm, và vẽ biểu đồ vị trí.
Giải thích kết quả phân tích biệt số
-Bảng Tests of Equality of Group Means
Nếu xem xét một cách riêng biệt thì chỉ có tính chất hoạt động của hộ (hộ chuyên hay hộ kiêm), số mặt hàng, vốn cố định, và tính chất làng nghề (đã và chưa được công nhận) có khả năng phân biệt một cách có ý nghĩa khác biệt giữa những hộ có lợi nhuận và những hộ không có lợi nhuận.
| TESTS OF EQUALITY OF GROUP MEANS | |||||
|---|---|---|---|---|---|
| WILKS’ LAMBDA | F | DF1 | DF2 | SIG. | |
| TUOI | .999 | .071 | 1 | 59 | .791 |
| NAMKINHNGHIEM | .998 | .138 | 1 | 59 | .712 |
| TÍNH CHẤT HỘ | .862 | 9.437 | 1 | 59 | .003 |
| TONG LAO DONG | .975 | 1.496 | 1 | 59 | .226 |
| SOMATHANG | .923 | 4.925 | 1 | 59 | .030 |
| VON CO DINH (1000D) | .922 | 4.988 | 1 | 59 | .029 |
| VON LUU DONG (1000D) | .962 | 2.322 | 1 | 59 | .133 |
| Tinh chat nghe | .721 | 22.785 | 1 | 59 | .000 |
– Bảng Eigenvalues. Vì trường hợp này chỉ có 2 nhóm (có lợi nhuận và không có lợi nhuận) nên chỉ có 1 hàm phân biệt được ước lượng. Giá trị eigen là 0.858 và chiếm đến 100% phương sai giải thích được nguyên nhân. Hệ số tương quan canonical tương ứng là 0.680, cho thấy 46% của phương sai biến phụ thuộc (lợi nhuận) được giải thích bởi mô hình này. (bình phương hệ số 0.680 = 0.46 = 46%).
| EIGENVALUES | ||||
|---|---|---|---|---|
| FUNCTION | EIGENVALUE | % OF VARIANCE | CUMULATIVE % | CANONICAL CORRELATION |
| 1 | .858A | 100.0 | 100.0 | .680 |
| a. First 1 canonical discriminant functions were used in the analysis. | ||||
-Tiếp theo sẽ xác định xem hàm phân biệt được ước lượng có ý nghĩa về mặt thống kê hay không. Với hệ số Wilk l là 0.538 và giá trị p là 0.000 nhỏ hơn mức ý nghĩa 5% rất nhiều, nên có thể kết luận sự phân biệt có ý nghĩa thống kê ở mức ý nghĩa 5%, và có thể tiến hành giải thích kết quả
| WILKS’ LAMBDA | ||||
|---|---|---|---|---|
| TEST OF FUNCTION(S) | WILKS’ LAMBDA | CHI-SQUARE | DF | SIG. |
| 1 | .538 | 34.068 | 8 | .000 |
-Kết quả được giải thích chi tiết như sau:
Tầm quan trọng của các biến được thể hiện qua độ lớn trị tuyệt đối của hệ số chuẩn hóa (bảng Standardized Canonical Discriminant Function Coefficients). Các biến có trị tuyệt đối hệ số chuẩn hóa càng lớn thì càng đóng góp nhiều hơn vào khả năng phân biệt của hàm. Hoặc có thể xem xét điều này tại bảng Structure Matrix, mức độ tác động của các biến được xếp theo thứ tự giảm dần.

Standardized Canonical Discriminant Function Coefficients
| FUNCTION | |
|---|---|
| 1 | |
| TUOI | .147 |
| NAMKINHNGHIEM | .316 |
| TÍNH CHẤT HỘ | .551 |
| TONG LAO DONG | .105 |
| SOMATHANG | .229 |
| VON CO DINH (1000D) | .464 |
| VON LUU DONG (1000D) | .197 |
| Tinh chat nghe | .816 |
Theo kết quả, ta thấy biến tính chất hoạt động của hộ là biến dự đoán quan trọng nhất dùng để phân biệt 2 nhóm lợi nhuận, tiếp đến là biến tính chất làng nghề, vốn cố định và số mặt hàng.
Dấu của các hệ số của tất cả các biến dự đoán đều dương cho thấy rằng những hộ tham gia làng nghề đã được công nhận, hộ chuyên sản xuất, vốn cố định và vốn lưu động càng cao, số mặt hang càng nhiều, tổng lao động nhiều, nhiều kinh nghiệm và tuổi chủ hộ càng cao thì hộ sẽ càng có khả năng có lợi nhuận.
– Đánh giá hàm phân biệt thông qua mẫu kiểm tra.
Bảng Classification Results cho thấy kết quả phân loại dựa trên mẫu phân tích. Tỷ lệ phân biệt đúng là (26+22)/61 = 0.787 = 78.7%, tỷ lệ này được tính dựa vào những mẫu nhà nghiên cứu đã chọn. Để kiểm tra tính đúng đắn của hàm phân biệt được ước lượng, ta phải thực hiện kiểm tra trên mẫu được chọn một cách ngẫu nhiên. Tỷ lệ này là (16+19)/61 = 0.574 = 57.4%. Có thể kết luận mô hình phân biệt này là khá tốt.
| CLASSIFICATION RESULTSA,B | ||||||
|---|---|---|---|---|---|---|
| LN 1 CAO – 0 THAP | PREDICTED GROUP MEMBERSHIP | TOTAL | ||||
| 0 | 1 | |||||
| CASES SELECTED | ORIGINAL | COUNT | 0 | 26 | 7 | 33 |
| 1 | 6 | 22 | 28 | |||
| % | 0 | 78.8 | 21.2 | 100.0 | ||
| 1 | 21.4 | 78.6 | 100.0 | |||
| CASES NOT SELECTED | ORIGINAL | COUNT | 0 | 16 | 17 | 33 |
| 1 | 9 | 19 | 28 | |||
| % | 0 | 48.5 | 51.5 | 100.0 | ||
| 1 | 32.1 | 67.9 | 100.0 | |||
| a. 78.7% of selected original grouped cases correctly classified. | ||||||
| b. 57.4% of unselected original grouped cases correctly classified. | ||||||
Như vậy việc thực hiện phân tích biệt số đã được thực hiện đồng thời với việc diễn giải chi tiết ý nghĩa