Khi phân tích CFA và SEM trên AMOS, với các bạn đang mới bắt đầu làm quen với công cụ này sẽ dễ mắc phải các lỗi cơ bản khiến phần mềm không thể thực hiện tính toán. Dưới đây là một số lỗi/vấn đề phổ biến và cách khắc phục.
1. Lỗi: Amos will require the following pairs of variables to be uncorrelated
Khi phân tích CFA, SEM, sau khi nhấp vào nút Calculate Estimate, một thông báo như hình bên dưới xuất hiện với nội dung: Amos will require the following pairs of variables to be uncorrelated.
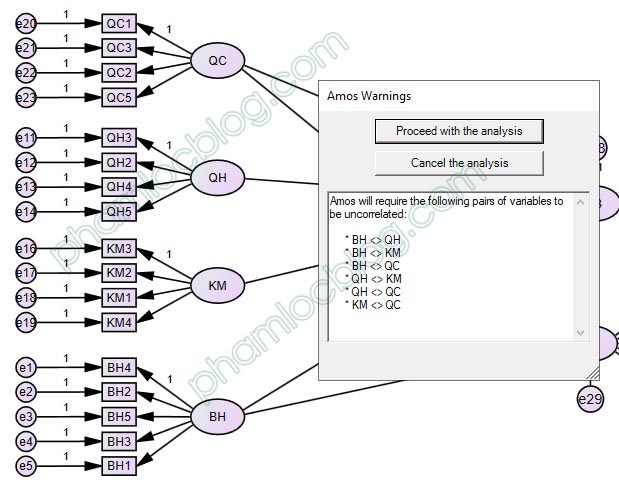
AMOS sẽ đưa ra cảnh báo này nếu chúng ta không nối các mũi tên 2 chiều để khai báo tham số tương quan giữa các biến độc lập trong mô hình. Nếu vấn đề này xuất hiện ở CFA, bạn cần nối các mũi tên 2 chiều cho tất cả các biến tiềm ẩn xuất hiện trong diagram. Nếu vấn đề xuất hiện ở SEM, bạn cần nối mũi tên 2 chiều cho tất cả các biến độc lập. Nếu bạn không xác định được nên kéo mũi tên cho biến nào, bạn hãy làm theo hướng dẫn ở thông báo: BH <> QH nghĩa là hãy nối mũi tên 2 chiều cho BH và QH.
2. Lỗi: Missing observations
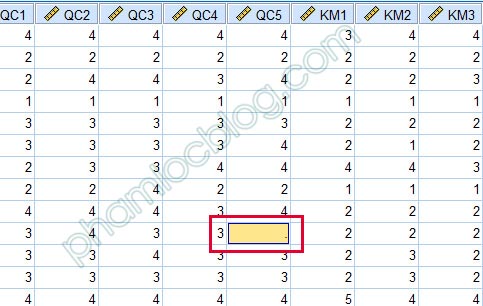
Khi thực hiện phân tích, chúng ta nhận được thông báo trả về với mô tả như sau: An error occurred while attempting to fit the model kèm với hình ảnh bên dưới.
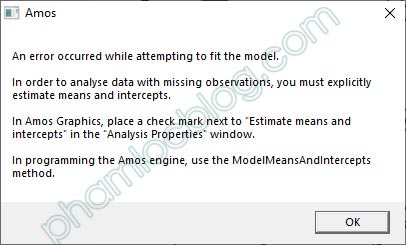
Vấn đề này xảy ra khi dữ liệu của chúng ta tồn tại missing. Ví dụ trong trường hợp này, biến QC5 trong tập dữ liệu có một ô missing dữ liệu tại quan sát số 10. Cách xử lý là chúng ta xóa đi quan sát số 10 này trên dữ liệu hoặc chúng ta điền giá trị missing vào. Nếu không xác định được giá trị missing, bạn có thể dùng giá trị mean làm tròn của cột QC5 để điền con số vào. Ví dụ: trung bình cộng mean của QC5 là 3.22, bạn điền và chỗ missing là 3.
3. Lỗi: The observed variable is represented by an ellipse in the path diagram
Khi phân tích chúng ta nhận được thông báo với nội dung: The observed variable, XXX, is represented by an ellipse in the path diagram.
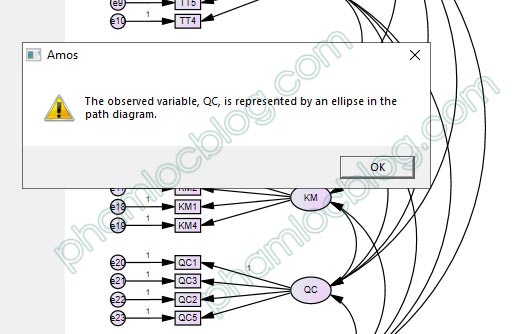
Vấn đề này thường phát sinh khi biến tiềm ẩn trong diagram CFA hay SEM trùng tên với một biến có sẵn dữ liệu trong tệp data. Cụ thể với trường hợp này, trong khuôn dữ liệu đã có biến QC và trên diagram AMOS, cũng có sự xuất hiện của biến tiềm ẩn QC, do vậy phần mềm sẽ báo có lỗi và không cho thực hiện phân tích.

Cách xử lý là chúng ta hoặc đổi tên biến trên khuôn dữ liệu hoặc tên biến tiềm ẩn trên diagram để 2 tên không trùng nhau là được. Bạn có thể thêm tiền tố f_ hay F_ là tiền tố phổ biến trong thống kê cho 1 trong 2 biến trùng nhau, ví dụ QC thành f_QC hoặc F_QC.
4. Lỗi: The following variables are endogenous, but have no residual (error) variables
Khi thực hiện phân tích SEM, chúng ta nhận được bảng cảnh báo bên dưới kèm với nội dung: The following variables are endogenous, but have no residual (error) variables.
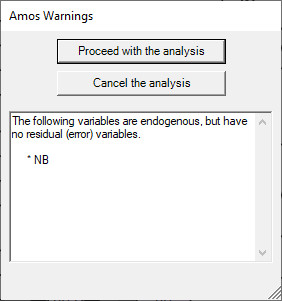
Lỗi này xảy ra trong SEM khi biến phụ thuộc hoặc các biến quan sát chúng ta không gắn phần dư hay sai số. Cụ thể trong trường hợp này, NB là biến phụ thuộc (nhận mũi tên tác động hướng về) nhưng chúng ta không gán phần dư vào.

Cách xử lý là chúng ta sẽ bổ sung thêm phần dư còn thiếu cho các biến phụ thuộc, bổ sung sai số còn thiếu cho các biến quan sát.

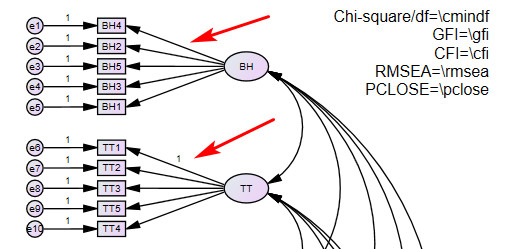
5. Lỗi: The model is probably unidentified hoặc The (probably) unidentified parameters are marked
Khi phân tích, icon View the output path diagram sẽ bị khóa, chúng ta không thể xem nhanh kết quả output trên diagram CFA hoặc SEM.
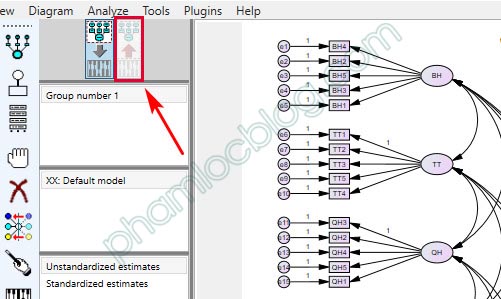
Kèm với đó là kết quả trong Output chúng ta nhận được các thông báo như: The model is probably unidentified. In order to achieve identifiability, it will probably be necessary to impose 1 additional constraint hoặc The (probably) unidentified parameters are marked.

Lỗi này phát sinh khi chúng ta không gán constrain hoặc regression weight cho 1 trong các mũi tên từ biến tiềm ẩn lên biến quan sát hoặc từ biến bậc 2 sang biến bậc 1. Hãy kiểm tra tất cả các construct trong diagram CFA hoặc SEM của bạn, có nhóm construct nào bạn bỏ sót regression weight là 1 cho một trong các mũi tên hay không, nếu có hãy bổ sung vào. Cụ thể trong trường hợp này, ở construct BH chúng ta không gán bất kỳ một regression weight nào cho các mũi tên từ BH lên các biến quan sát. Do vậy khi phân tích chúng ta nhận được thông báo Regression Weight ở các biến quan sát đều là unindentified.
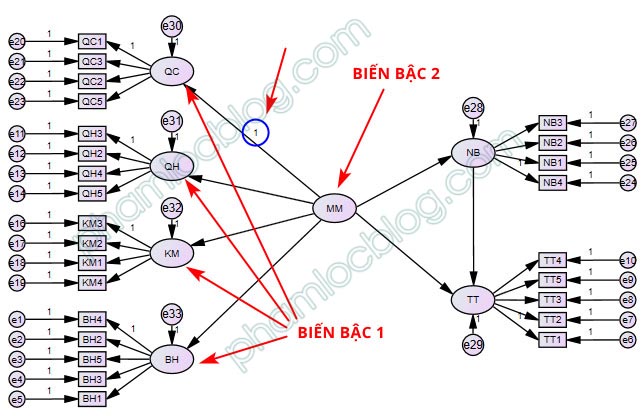
Việc gán regression weight cho một trong các mũi tên cũng cần được áp dụng khi bạn có các biến bậc hai. Ví dụ trong diagram bên dưới, MM là biến bậc hai của 4 biến bậc một QC, QH, KM, BH. Khi biểu diễn trên diagram, chúng ta cần gán regression weight là 1 cho một trong các mũi tên từ biến bậc hai sang bậc một.