Chat GPT là một trợ lý trò chuyện bằng tuệ nhân tạo do công ty OpenAI phát triển. Phần mềm này cung cấp cho người dùng một công cụ để tìm kiếm thông tin, giải đáp và hỗ trợ trả lời các câu hỏi của công
Chất lượng của một Tạp chí chủ yếu được đánh giá dựa trên (i) quy trình kiểm duyệt để đăng bài, và (ii) các thống kê về chỉ số được trích dẫn của các bài báo đăng trên Tạp chí đó thông qua chỉ số ảnh
Tại sao phải công bố bài báo khoa học? Trong hoạt động nghiên cứu khoa học, các bài báo khoa học đóng một vai trò rất quan trọng. Nó không chỉ là một bản báo cáo về một công trình nghiên cứu, mà còn là một
Bài báo khoa học là gì? Nghiên cứu khoa học ngày nay đã trở thành một phần không thể thiếu trong đời sống học thuật. Khi nghiên cứu được triển khai thực hiện và có kết quả thì kết quả nghiên cứu đó cần được chia
Luận văn hay luận án tiến sĩ là công trình nghiên cứu của nghiên cứu sinh về một chủ đề nghiên cứu chuyên sâu nào đó. Về cấu trúc, một luận án tiến sĩ chuyên ngành kinh tế – quản trị được tổ chức theo bố
Luận văn hay luận án tốt nghiệp của sinh viên đại học hoặc trình độ thạc sĩ nhằm mục đích nghiên cứu chuyên sâu về một chủ đề nghiên cứu nào đó. Về cấu trúc, một khóa luận tốt nghiệp chuyên ngành kinh tế – quản
Báo cáo thực tập chuyên ngành là báo cáo tốt nghiệp của sinh viên hệ đại học hoặc thạc sĩ thực hành chuyên ngành, thực hiện gắn liền với quá trình thực tập chuyên ngành từ 4 – 12 tháng trong một đơn vị tổ chức
Báo cáo thực tập nhận thức là báo cáo tốt nghiệp của sinh viên hệ đại học thực hành, thực hiện gắn liền với quá trình thực tập nhận thức 2 – 6 tháng trong một đơn vị tổ chức doanh nghiệp. Mục đích chính của
1. GIỚI THIỆU Nhiều người cho rằng viết báo cáo/nghiên cứu là để truyền tải thông tin. Tuy nhiên một bài viết hiệu quả còn hơn thế. Nó phải: Làm thay đổi cách nhìn nhận vấn đề của người đọc Thuyết phục người đọc tin vào
Sau khi đã xử lý xong dữ liệu từ bảng hỏi khảo sát điều tra, đảm bảo các yêu cầu về quy mô mẫu tối thiểu, nhà nghiên
Một nghiên cứu khoa học thường được triển khai thực hiện qua 8 bước cơ bản (Kumar, 2011): Giai đoạn I: Lựa chọn và quyết định chủ đề
Trong nghiên cứu khoa học, phương pháp định lượng và định tính có vai trò rất lớn đối với đề tài nghiên cứu, hai phương pháp này sẽ
If the subject into which you conduct research is a scientific subject or topic, then the research methods include experiments, tests, the study of many other results of
Bạn có đam mê với nghiên cứu khoa học? Vậy tại sao không thử sức trong một đề tài nghiên cứu tự chọn theo chuyên môn của mình?
Phân tích lí thuyết là thao tác phân tài liệu lý thuyết thành các đơn vị kiến thức, cho phép ta có thể tìm hiểu những dấu hiệu đặc thù, bản chất, cấu trúc bên trong của lí thuyết. Từ đó mà nắm vững bản chất của từng đơn vị
1. Phương pháp phân tích và tổng hợp lý thuyết Nghiên cứu lý thuyết thường bắt đầu từ phân tích các tài liệu để tìm ra cấu trúc, các xu hướng phát triển của lý thuyết. Từ phân tích lý thuyết, lại cần tổng hợp chúng lại để xây dựng
Nghiên cứu định tính nhằm mục đích thu thập một sự hiểu biết sâu sắc về hành vi con người và lý do ảnh hưởng đến hành vi này. Các phương pháp định tính điều tra lý do tại sao và làm thế nào trong việc ra quyết định, không chỉ trả lời các
Phương pháp nghiên cứu định tính gồm các phương pháp không sử dụng các thang đo lường thống kê. Bất chấp xu thế đề cao phương pháp định lượng hiện nay, phương pháp định tính vẫn khẳng định giá trị như là phương pháp lâu đời đã được sử dụng
Nghiên cứu định lượng (Quantitative research) là điều tra thực nghiệm có hệ thống về các hiện tượng quan sát được qua số liệu thống kê, toán học hoặc số hoặc kĩ thuật vi tính. Cũng có thể hiểu: Nghiên cứu định lượng là phương pháp thu thập dữ liệu bằng
Trong phương pháp khảo sát điều tra (survey research), nhà nghiên cứu hỏi đối tượng khảo sát một số câu hỏi về một hoặc một vài chủ đề nào đó. Khảo sát có thể được tiến hành trực tuyến, qua thư điện tử email, thư bưu điện, phát trực tiếp
PHẦN MỀM HKT SOFT Hoàn toàn do người Việt xây dựng và triển khai
CÔNG NGHỆ VƯỢT TRỘI, TÍCH HỢP PHẦN CỨNG Giải pháp phần mềm bán hàng và quản lý khoa học, ứng dụng cộng nghệ 4.0
TƯ VẤN HỖ TRỢ VẢ BẢO HÀNH TRỌN GÓI Dịch vụ hỗ trợ và bảo trì bảo hành đảm bảo vận hành sản xuất kinh doanh và bán hàng thường xuyên
TƯ VẤN QUẢN LÝ TỔNG THỂ Tư vấn quản lý ứng dụng phần mềm thích ứng với đặc thù từng khách hàng
Trong nghiên cứu kinh tế liên quan tới việc phân tích các dữ liệu sơ cấp và thống kê dữ liệu. SPSS là phần mềm được đông đảo thành viên trong cộng đồng nghiên cứu ưu tiên sử dụng vì giao diện đồ họa trực quan và khả năng phân
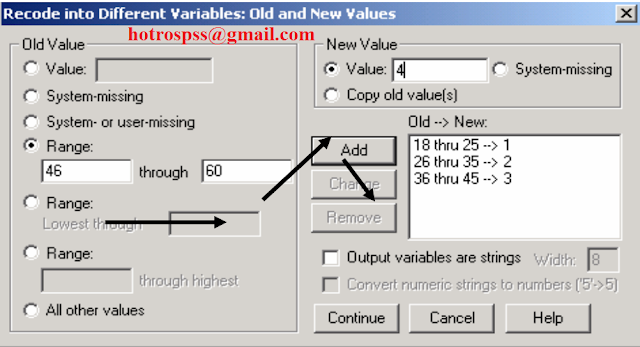
Vấn đề: Thông thường khi làm luận văn với phương pháp hồi quy thì phân tích nhân tố chia làm hai bước – Phân tích
Câu hỏi đảo, câu hỏi ngược reverse code là gì? Trong thang đo likert, có thể trong cùng 1 nhân tố các bạn sẽ gặp
Hiện nay phần mềm STATA đang được sử dụng rất nhiều vào phân tích dữ liệu. Với việc cập nhật liên tục các chức năng mới, STATA đang trở thành công cụ mạnh trong phân tích dữ liệu cùng với các phần mềm khác như phần mềm EVIEWS, phần mềm
1. GIỚI THIỆU Mục đích của đa số các nghiên cứu thực nghiệm trong kinh tế là giải thích mối quan hệ giữa một biến
Mình sẽ dùng bộ dữ liệu “Low Birth Weight” để minh họa (Để dùng bộ dữ liệu này thì các bạn gõ lệnh webuse lbw trong cửa
Phần mềm phân tích số liệu là một công cụ không thể thiếu đối với các nhà nghiên cứu và thống kê. Hiện nay, có rất nhiều phần mềm chuyên dụng phục vụ cho việc xử lý và phân tích số liệu thống kê. Ví dụ như: SAS, SPSS, STATA,
Trang https://phuongphapnghiencuu.com/ được lập ra để nghiên cứu các tài liệu tiếng Việt, tiếng Anh về SPSS,AMOS, CFA, Mô hình SEM, quy trình, các thủ
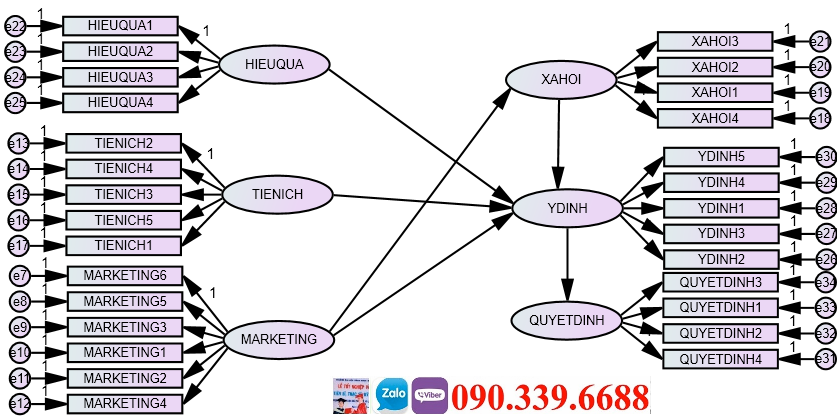
Phần thứ 1: 1. Giới thiệu tổng quan mô hình mạng (SEM) Một trong những kỹ thuật phức hợp và linh hoạt nhất sử dụng
1. Khái niệm phương pháp nghiên cứu Phương pháp được hiểu (i) là cách thức nghiên cứu, nhìn nhận các hiện tượng của tự nhiên và đời sống xã hội, ví dụ: phương pháp biện chứng, phương pháp so sánh thực nghiệm; (ii) là hệ thống các cách sử dụng
Tại sao phải công bố bài báo khoa học? Trong hoạt động nghiên cứu khoa học, các bài báo khoa học đóng một vai trò rất quan trọng. Nó không chỉ là một bản báo cáo về một công trình nghiên cứu, mà còn là một đóng góp cho kho
Bài báo khoa học là gì? Nghiên cứu khoa học ngày nay đã trở thành một phần không thể thiếu trong đời sống học thuật. Khi nghiên cứu được triển khai thực hiện và có kết quả thì kết quả nghiên cứu đó cần được chia sẻ. Bài báo khoa
Luận văn hay luận án tiến sĩ là công trình nghiên cứu của nghiên cứu sinh về một chủ đề nghiên cứu chuyên sâu nào đó. Về cấu trúc, một luận án tiến sĩ chuyên ngành kinh tế – quản trị được tổ chức theo bố cục, với các nội
Phương pháp luận là lý luận về phương pháp, là hệ thống các quan điểm, các nguyên tắc chỉ đạo con người tìm tòi, xây dựng, lựa chọn và vận dụng các phương pháp trong nhận thức và thực tiễn. Hiện có ba cách hiểu phổ biến nhất về phương pháp
Trong nghiên cứu khoa học, phương pháp định lượng và định tính có vai trò rất lớn đối với đề tài nghiên cứu, hai phương pháp này sẽ giúp nhà nghiên cứu thu thập dữ liệu một cách chính xác và nhanh chóng tuy nhiên hai phương pháp này lại